В этой статье мы объясним использование утилиты grep на различных примерах. Мы будем использовать Debian 10 для объяснения команд и методов, упомянутых в этой статье.
Установка Grep
Grep установлен в большинстве дистрибутивов Linux. Однако в случае, если он отсутствует в вашей системе, вы можете установить его, используя следующий метод в Терминале:
$судо apt-get install рукоятка
Использование Grep
Вот основной синтаксис команды grep. Он начинается с grep, за которым следуют некоторые параметры и критерии поиска, а затем заканчивается именем файла.
$рукоятка [параметры]ШАБЛОН[ФАЙЛ...]
Искать файлы
Чтобы найти имя файла в каталоге, содержащем определенную строку, вы можете использовать команду grep следующим образом:
$ls - | рукоятка -янить
Например, для поиска имени файла, содержащего строку тестовое задание , команда будет такой:
$ls-| рукоятка-ятестовое заданиеЭта команда выводит список всех файлов, содержащих строку тестовое задание .

Искать строку в файле
Для поиска строки в определенном файле вы можете использовать следующий синтаксис команды:
$рукояткастрока имя файлаНапример, чтобы найти строку тестовое задание в файле с именем testfile1 , мы использовали следующую команду :
$рукояткасотрудник testfile1 
Приведенный выше вывод вернул предложение из testfile1 который содержит строку работник .
Искать строку в нескольких файлах
Для поиска строки в нескольких файлах можно использовать следующий синтаксис команды:
$рукояткастрока имя_файла1 имя_файла2Например, для поиска строкового сотрудника в наших двух файлах testfile1 и testfile2 мы использовали следующую команду:
$рукояткасотрудник testfile1 testfile2 
Приведенная выше команда перечислит все строки, содержащие строку employee из файлов testfile1 и testfile2.
Вы также можете использовать подстановочный знак, если все имена файлов начинаются с одного и того же текста.
$рукояткастрока имя файла*Например, если мы возьмем приведенный выше пример, в котором наши имена файлов были testfile1 и testfile2 , команда будет такой:
$рукояткатестовый файл сотрудника* 
Искать строку в файле, игнорируя регистр строки
Чаще всего вы сталкиваетесь с этим, когда ищете что-то с помощью grep, но не получаете результат. Это происходит из-за несоответствия регистра при поиске строки. Как и в нашем примере, если мы по ошибке используем Работник вместо того работник , он вернет nil, поскольку наш файл содержит строку работник строчными буквами.

Вы можете указать grep игнорировать регистр строки поиска, используя флаг –i после grep следующим образом:
$рукоятка–I строка имя файла 
Используя флаг –i, команда выполнит поиск без учета регистра и вернет все строки, содержащие строку работник в нем без учета букв прописные или строчные.
Поиск с использованием регулярного выражения
При правильном использовании регулярное выражение - очень эффективная функция в grep. С помощью команды Grep вы можете определить регулярное выражение с начальным и конечным ключевыми словами. При этом вам не нужно будет вводить всю строку с помощью команды grep. Для этой цели можно использовать следующий синтаксис.
$рукоятканачальное ключевое слово.*endKeyword имя файлаНапример, для поиска строки в файле с именем testfile1, которая начинается со строки this и заканчивается строковыми данными, мы использовали следующую команду:
$рукояткаэто.*data testfile1 
Он напечатает всю строку из testfile1 содержащее выражение (начальное ключевое слово this и конечное ключевое слово data).
Вывести определенное количество строк после / перед поисковой строкой
Вы также можете отобразить определенное количество строк в файле до / после совпадения строки вместе с самой совпадающей строкой. Для этого можно использовать следующий синтаксис:
$рукоятка -К <N>строка имя файлаПосле сопоставления строки в указанном файле, включая сопоставленную строку, отобразится количество N строк.
Например, это наш образец файла с именем testfile2 .
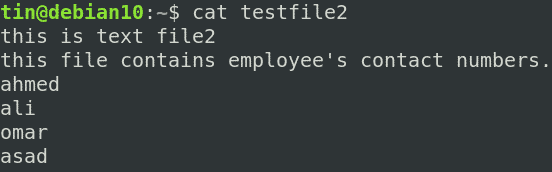
Следующая команда выведет совпадающую строку, содержащую строку работник , вместе с двумя строками после него.
$рукоятка-К2–I сотрудник testfile2 
Точно так же, чтобы отобразить количество N строк перед совпадающей строкой в конкретном файле, используйте следующий синтаксис:
$рукоятка -B <N>строка имя файлаЧтобы отобразить N строк вокруг строки в конкретном файле, используйте следующий синтаксис:
$рукоятка -C <N>строка имя файлаВыделение поиска
Grep по умолчанию печатает совпадающие строки, но не показывает, какая часть строки совпадает. Если вы используете опцию –color с grep, она покажет, где строки обработки появляются в вашем файле. Grep по умолчанию использует красный цвет для выделения.
Для этого можно использовать следующий синтаксис:
$рукояткастрока имя файла--цвет 
Подсчет количества совпадений
Если вы хотите подсчитать, сколько раз конкретное слово встречается в конкретном файле, вы можете использовать команду grep с параметром –c. Он возвращает только количество совпадений, а не сами совпадения. Для этого можно использовать следующий синтаксис:
$рукоятка–C строка имя файлаЭто наш пример файла выглядит так:

Ниже приведен пример команды, которая вернула, сколько раз слово файл появился в файле с именем testfile3 .

Перевернутый поиск
Иногда вам нужно выполнить обратный поиск, который отображает все строки, кроме тех, которые совпадают с вводом. Для этого просто используйте флаг –v, за которым следует grep:
$рукоятка–V строка имя файлаНапример, чтобы отобразить все строки в файле testfile3 которые не содержат слова account, мы использовали следующую команду:
$рукоятка–V account testfile3 
Использование Grep с другими командами
Grep также можно использовать для фильтрации требуемого результата из вывода различных команд. Например, из apt –installed список вывод команды, вы хотите найти только пакеты, которые были установлены автоматически, вы можете отфильтровать результат с помощью grep следующим образом:
$подходящий--установленысписок| рукояткаавтоматический 
Аналогичным образом lscpu предоставляет подробную информацию о процессоре. Если вас просто интересует информация об архитектуре ЦП, вы можете отфильтровать ее, используя следующую команду:
$lscpu| рукояткаАрхитектура 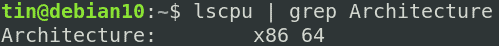
В этой статье мы описали несколько примеров, которые помогут вам разобраться в командах grep и их использовании в различных условиях. Хороший контроль над командой grep может сэкономить много времени, если вам нужно просмотреть большие файлы конфигурации или журналов и пролистать через них полезную информацию.