
Мы увидим практическое выполнение этой функции в этом уроке.
Пример 1. Использование метода Pandas Series.Reset_Index() для сброса индекса серии, чтобы сохранить исходный список индексов в виде столбца
На этой иллюстрации используется метод «Series.reset_index ()», чтобы сбросить индекс серии Pandas и сохранить изменения в копии серии.
Работа программы Python началась с поиска подходящего инструмента для нашей системы для выполнения сценария. Для выполнения программ выбран инструмент «Spyder».
Мы инициализируем скрипт, загружая сначала необходимые библиотеки. Поскольку метод «Series.reset_index ()» используется из набора инструментов Pandas, нам обязательно нужно загрузить его в нашу среду Python. Библиотека Pandas импортируется путем написания сценария «import pandas as pd». Раздел «as pd» в этой строке относится к тому, чтобы сделать «pd» псевдонимом библиотеки «Pandas». Следовательно, нам не нужно использовать «Панды». Вместо этого мы просто пишем «pd», чтобы получить доступ к любой функции Pandas.
Первый метод, к которому мы обращаемся из модуля Pandas с помощью псевдонима «pd», — это метод «pd.Series». Этот метод является встроенным методом Pandas для создания серии с предоставленным массивом значений. Мы вызываем эту функцию и указываем значения: «34», «21», «18», «45», «76», «82», «22», «40», «91», «101», и «8». Кроме того, имя столбца определяется с помощью параметра «имя» как «Данные».
После этого мы инициализируем переменную «new_index» и присваиваем ей некоторые значения, но с той же длиной, которую мы использовали для значений в серии. Значения для переменной «new_index»: «A01», «A02», «A03», «A04», «A05», «A06», «A07», «A08», «A09», «A10» и «А11». Мы используем значения, хранящиеся в этой переменной, для индекса. Чтобы установить столбец индекса серии, мы вызываем свойство «Series.index» и присваиваем ему переменную «new_index». Значения, хранящиеся в «new_index», помещаются в качестве индекса серии вместо списка индексов по умолчанию, который начинается с «0». Наконец, чтобы увидеть серию с указанным индексом, мы вызываем функцию «print ()» и передаем серию «Число» в качестве входных данных для печати ее содержимого.
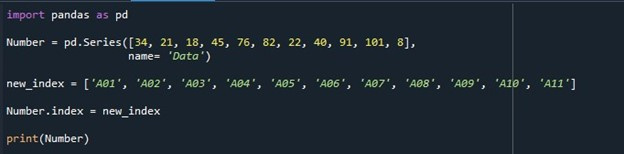
Результирующая серия с указанными индексами, заменившая список индексов по умолчанию, выставляется на терминал.
Чтобы сбросить этот пользовательский список индексов до списка по умолчанию, мы используем метод Pandas «Series.reset_index ()».
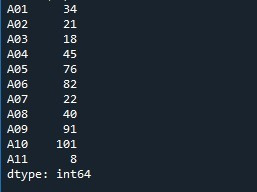
Мы вызываем метод «Series.reset_index ()», чтобы сбросить список индексов. Имя серии предоставляется как «Число» с помощью метода «reset_index ()». Таким образом, он работает путем проверки серии и сброса списка индексов к настройкам по умолчанию. Чтобы сохранить эти изменения, мы создаем переменную «Вывод», которая генерирует копию серии с измененным списком индексов. Мы используем функцию «print()» для отображения «выходного» содержимого.

На выходном изображении мы видим, что отображается последовательный индекс по умолчанию. Кроме того, указанный список индексов добавляется как новый столбец серии с меткой «индекс».
Пример 2. Использование метода Pandas Series.Reset_Index() для сброса индекса серии и удаления исходного индекса
Этот пример демонстрирует технику сброса индекса серии Pandas с использованием метода «Series.reset_index ()». Кроме того, мы отбрасываем первоначально определенный столбец индекса, используя параметр «удалить» функции «Series.reset_index ()».
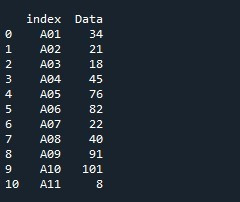
Для выполнения фрагмента кода мы сначала импортируем библиотеку Pandas как «pd». Затем мы применяем метод из загруженного в данный момент модуля Pandas для создания серии Pandas. Используется функция «pd.Series()», и мы предоставляем ей массив значений для создания серии с использованием этих значений. Значения, которые мы указали для построения ряда, имеют строковый тип данных. Это «Nestle», «Cadbury», «Mars», «Dove», «Lindt», «Godiva», «Ghirardelli» и «Ferrero». Мы используем параметр «имя», чтобы пометить этот столбец. Мы называем его «Бренд», поскольку мы создаем серию, которая содержит названия брендов шоколада. Длина серии равна 8. Создается объект серии «Шоколад», которому присваивается результат, полученный в результате вызова метода Pandas «pd.Series ()».
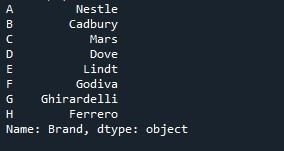
Кроме того, создается и инициализируется переменная «идентификатор» с этими значениями «A», «B», «C», «D», «E», «F», «G» и «H». Длина содержащихся в нем значений такая же, как и длина значений ряда. Теперь мы изменим список индексов серии по умолчанию и укажем значения переменной «идентификатор», которые будут использоваться в качестве индекса. Для установки индекса используется свойство «Series.index». Название серии «Шоколадки» упоминается со свойством «.index». Мы присваиваем переменную «идентификатор» свойству index. Свойство «индекс» извлекает значения, сохраненные в переменной «идентификатор», и делает их индексным списком серий. В конечном итоге метод «print()» вызывается для печати серии «Chocolates».
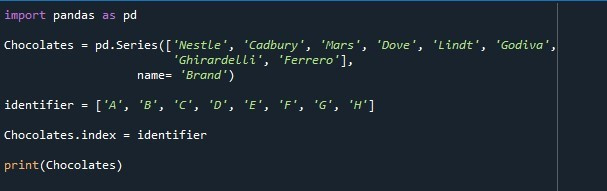
Серия, показанная на следующем снимке, показывает, что мы успешно разместили указанный список индексов вместо списка индексов по умолчанию.
Теперь, если вы хотите сбросить настройки индекса, просто используйте метод Pandas «Series.reset_index ()». С помощью этого метода мы предоставляем название нашей серии. Он просто сбрасывает настройки индекса по умолчанию для этой конкретной серии.
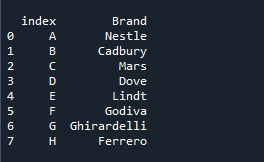
Мы вызываем метод «Series.reset_index ()» и задаем имя серии как «Шоколад». Чтобы сохранить серию со списком индексов по умолчанию, мы создаем переменную «ser». Теперь нам нужно посмотреть этот сериал. Для этого используется метод «print()». В его фигурных скобках мы передаем переменную «ser», чтобы она отображала все, что эта переменная сохранила.

Результирующая серия отображается в списке индексов по умолчанию. Но также изначально указанный индексный список присутствует в виде столбца в ряду с заголовком «индекс». Метод «reset_index()» размещает список индексов по умолчанию, но не удаляет указанный список для индекса и вместо этого сохраняет его как новый столбец.
Чтобы отбросить первоначально указанный список индексов, который теперь добавляется как столбец в серию, мы используем параметр в методе «reset_index()». Этот параметр является «падением». Он принимает логическое значение в качестве входных данных. По умолчанию для параметра drop установлено значение False, что означает, что исходный список индексов не удаляется. Поскольку мы хотим удалить первоначальный список индексов, мы должны изменить его значение на «True».
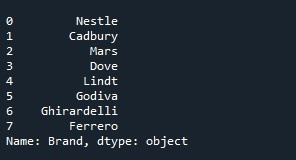
Мы просто передаем атрибут «drop» со значением «True» в функцию «Series.reset_index()».

Отрендеренные выходные данные демонстрируют серию, в которой теперь удален столбец «индекс» и который отображается со списком индексов по умолчанию. Полученный результат представлен на следующем снимке:
Вывод
Вы можете использовать наборы данных, в которых указан ваш список индексов, вместо списка индексов по умолчанию. Возможно, нам придется сбросить его до настроек по умолчанию. По этой причине Pandas предоставляет нам метод Series.reset_index(). Этот метод изменяет индекс на настройки по умолчанию. Мы предоставили две техники для использования этого метода. Для первой иллюстрации мы сохранили первоначально указанный список индексов в результирующем ряду в виде столбца после добавления списка индексов по умолчанию. Другой метод демонстрировал, как удалить указанный список из серии с помощью параметра «удалить».