«Значения, разделенные запятыми (CSV), — один из самых универсальных и простых в использовании форматов данных. Это облегченный формат данных, который позволяет разработчикам и приложениям передавать и анализировать данные из одного источника в другой.
Данные CSV хранят данные в табличном формате, где каждый столбец отделяется запятой, а новая запись размещается на новой строке. Это делает его очень хорошим выбором для экспорта баз данных, таких как базы данных SQL, данные Cassandra и многое другое.
Поэтому неудивительно, что вы столкнетесь со сценарием, в котором вам нужно импортировать CSV-файл в вашу базу данных.
Цель этого руководства — показать вам быстрый и простой способ импорта CSV-файла в ваш кластер Elasticsearch с помощью панели управления Kibana».
Давайте вскочим.
Требования
Перед погружением убедитесь, что у вас есть следующие требования:
- Кластер Elasticsearch с зеленым статусом работоспособности.
- Сервер Kibana подключен к вашему кластеру Elasticsearch.
- Достаточные разрешения для управления индексами в вашем кластере.
Образец CSV-файла
Как обычно, первым требованием является исходный CSV-файл. Хорошо убедиться, что данные в вашем CSV-файле правильно отформатированы и не содержат ошибок.
Для иллюстрации мы будем использовать бесплатный набор данных, содержащий фильмы и телешоу из Amazon Prime.
Откройте браузер и перейдите к ресурсу ниже:
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
Следуйте процедуре загрузки набора данных на локальный компьютер. Распаковать скачанный архив можно командой:
$ распаковать а~ / Загрузки / архив.zip
Импорт файла CSV
Как только у вас будет готов исходный файл, мы можем продолжить и обсудить, как его импортировать.
Начните с перехода на домашнюю панель управления Kibana и выбора опции «загрузить файл».
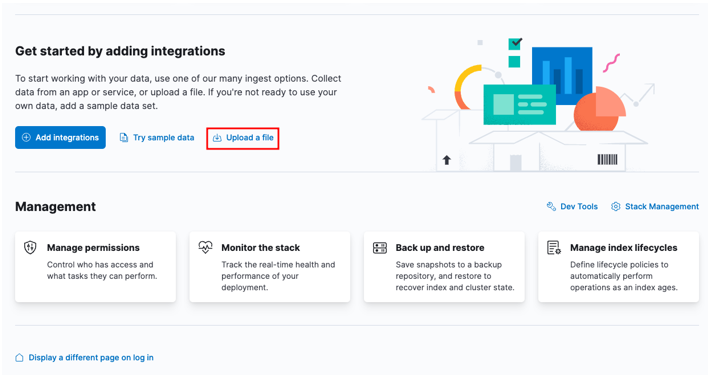
Найдите целевой файл CSV, который вы хотите импортировать, в окне запуска.
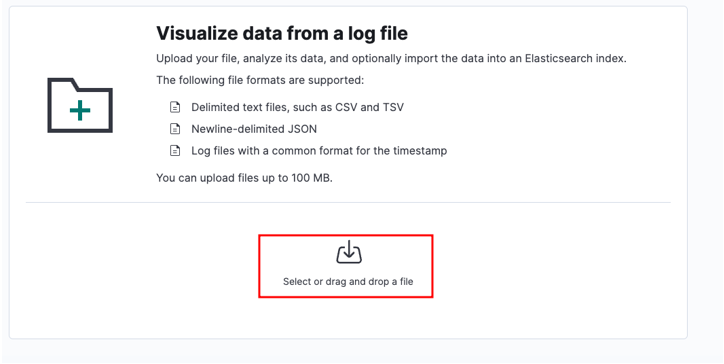
Выберите исходный файл и нажмите «Загрузить».
Разрешить Elasticsearch и Kibana анализировать загруженный файл. Это проанализирует файл CSV и определит формат данных, поля, типы данных и т. д.
ПРИМЕЧАНИЕ. В зависимости от конфигурации вашего кластера и размера данных этот процесс может занять некоторое время. Убедитесь, что главный узел отвечает, чтобы избежать тайм-аутов.
После завершения процесса вы должны получить образец содержимого вашего файла и статистику файла, проанализированную Elastic.
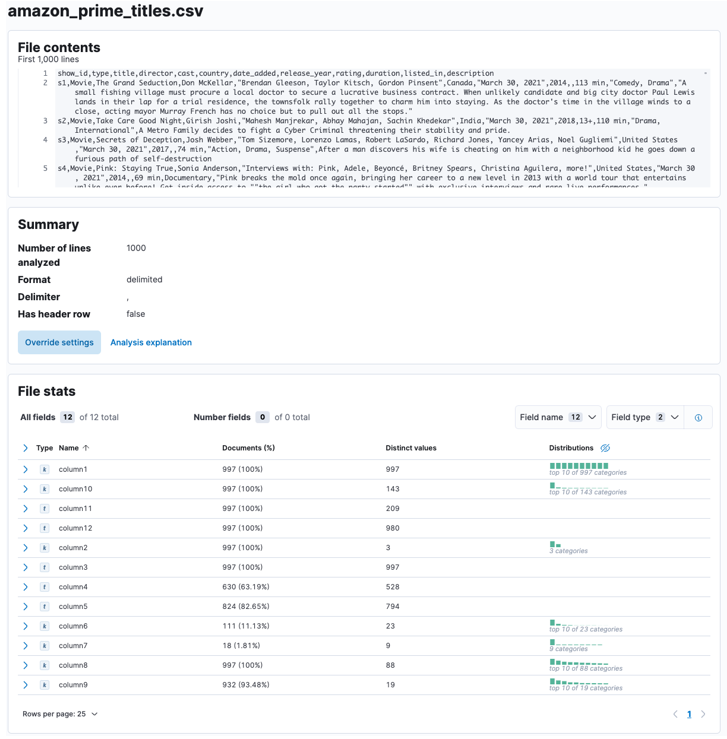
Вы можете настроить многочисленные параметры, например, разделитель, строки заголовков и т. д. Например, мы можем настроить приведенный выше вывод, чтобы сообщить Elastic, что наш CSV-файл содержит файлы заголовков.
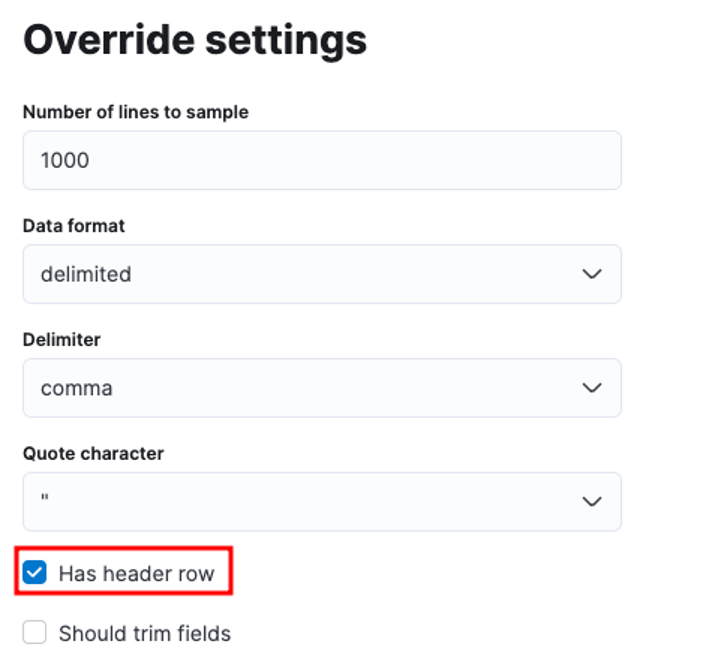
Затем мы можем нажать «Применить» и повторно проанализировать данные. Это должно отформатировать данные в правильном формате, включая поля.
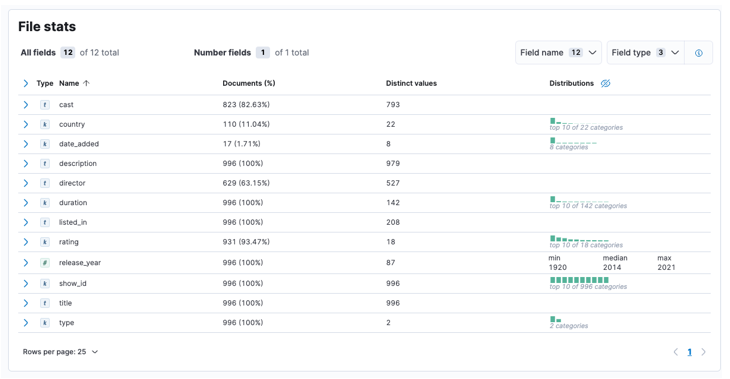
Затем мы можем нажать «Импорт», чтобы перейти к импортированной панели инструментов.
Здесь нам нужно создать индекс, в котором хранятся данные CSV. Вы можете присвоить вашему индексу любое поддерживаемое имя.
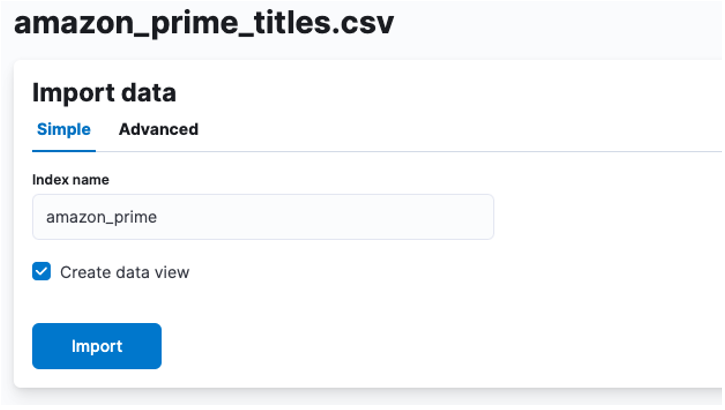
Если вы хотите настроить свойства индекса, такие как количество сегментов, реплик, сопоставлений и т. д., выберите расширенный параметр и настройте параметры по своему усмотрению.
Наконец, нажмите «Импорт» и наблюдайте, как Kibana делает свое «волшебство». После завершения вы можете получить доступ к своему индексу либо через Elasticsearch API, либо с помощью панели инструментов Kibana.
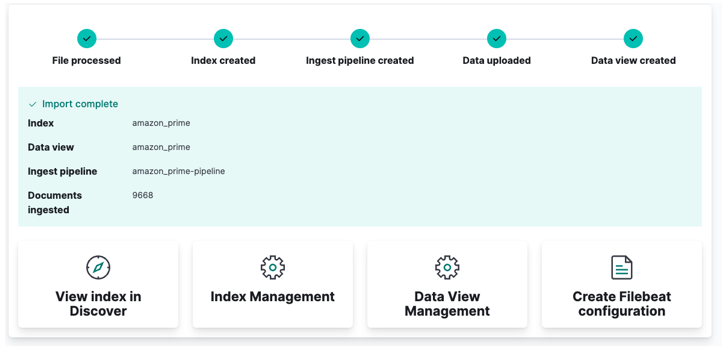
И вы сделали!!
Вывод
В этом посте мы рассмотрели процесс получения и импорта вашего набора данных CSV в ваш кластер Elasticsearch с помощью панели управления Kibana.
Спасибо за чтение и удачного кодирования!