киль (Извлечение знаний на основе эволюционного обучения) — это программный инструмент на основе Java, который специализируется на реализации эволюционных алгоритмов. Поскольку это открытый исходный код, он предоставляет широкий спектр алгоритмов обнаружения знаний, которые можно использовать в экспериментах, поддерживающих сообщество интеллектуального анализа и анализа данных. Он предоставляет простой и удобный в использовании графический пользовательский интерфейс, который значительно снижает общую сложность этого инструмента. Большинство подобных инструментов на рынке требуют, чтобы пользователи взаимодействовали с ними путем написания кода, тогда как Keel устраняет это требование, предоставляя интуитивно понятный графический интерфейс, который может использоваться как новичками, так и экспертами.
Keel предоставляет широкий спектр различных алгоритмов на основе вычислительного интеллекта, включая классификацию, регрессию, извлечение признаков, анализ шаблонов, кластеризацию и многое другое. С основными моделями, встроенными прямо в само приложение, Keel является очень полезным инструментом, когда дело доходит до проведения исследовательского анализа наборов необработанных данных. Его простой интерфейс перетаскивания в сочетании с простотой использования функциональных возможностей позволяет быстро и эффективно экспериментировать с интеллектуальным анализом данных как в образовательных, так и в исследовательских целях. Такие инструменты, как Keel, становятся все более популярными из-за их упрощенного подхода к сложным алгоритмическим методам.
Монтаж
Есть два основных способа установки киль на любой Linux-машине. Первый предполагает посещение Веб-страница киля и загрузка программного обеспечения оттуда. Второй, которому мы будем следовать в этом руководстве по установке, требует от нас загрузки Keel с помощью wget инструмент загрузки, доступный для пользователей Linux.
1. Начнем с получения wget на нашей Linux-машине.
Выполните следующую команду, чтобы загрузить wget с помощью подходящий менеджер пакетов:
$ судо apt-получить установку wget
Вы увидите аналогичный вывод терминала:
2. Теперь, когда у нас есть wget инструмент, установленный на нашем компьютере с Linux, мы используем его для загрузки киль инструмент.
Это ссылка на сайт что мы переходим к wget.
Запустите следующую команду в своем терминале:
$ wget http: // sci2s.ugr.es / киль / программного обеспечения / прототипы / openVersion / Программного обеспечения- 2018 -04-09.zip
Вы должны увидеть аналогичный вывод на своем терминале:
Как только Keel закончит загрузку, мы можем продолжить оставшуюся часть установки.
3. Теперь мы извлекаем сжатый файл, загруженный на предыдущем шаге, с помощью инструмента Linux Unzip.
Выполните следующую команду:
$ распаковать Программного обеспечения- 2018 -04-09.zip
Вы должны увидеть аналогичный вывод в терминале:
4. Перейдите в папку Keel, выполнив следующую команду:
$ CD Программного обеспечения- 2018 -04-09 / документы / эксперименты / КИЛЬ / расстояние /
5. Запустите следующую команду, чтобы начать установку:
$ Ява -банка . / GraphInterKeel.jar
При этом Keel должен быть доступен для использования на вашем компьютере с Linux.
Гид пользователя
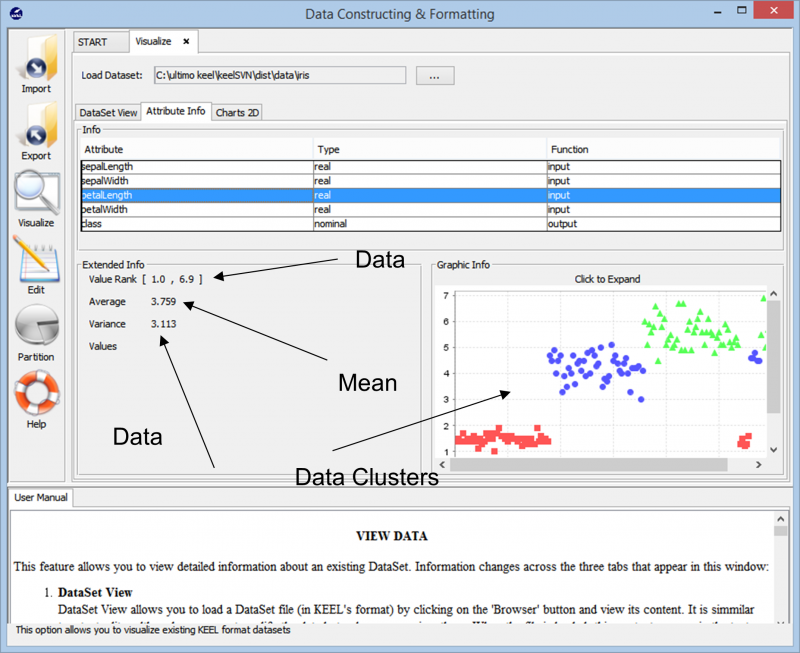
Взаимодействие с киль Приложение действительно легкое и простое. Начнем с импорта Набор данных по радужной оболочке в наше рабочее пространство.
Когда мы импортируем данные, инструмент показывает нам общую кластеризацию точки данных в наборе данных. Он также показывает нам различные классы, которые присутствуют в наборе данных, а также основную информацию, такую как числовые диапазоны, которые охватывают эти точки данных, а также общую дисперсию и средние значения, которые он представляет. Эта информация позволяет пользователям лучше понять, как выполнять подготовку данных для любой задачи анализа данных.
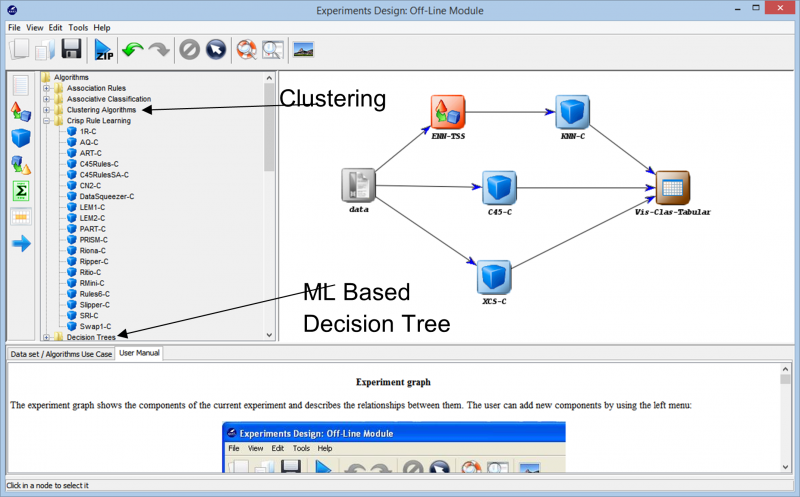
Продолжая экспериментировать, мы сталкиваемся с различными методами, которые можно использовать для создания нашего эксперимента на любом наборе данных. Различные алгоритмы обучения, которые можно использовать с нашими данными, можно увидеть на следующем изображении. В зависимости от характера набора данных и требований эксперимента можно экспериментировать с различными алгоритмами.
Например, если вы работаете с неразмеченными данными и должны найти сходство между различными точками данных в вашем наборе данных, использование алгоритма кластеризации из различных доступных вариантов может помочь вам лучше понять точки данных. Это в конечном итоге поможет вам пометить и классифицировать точки данных, чтобы эксперимент можно было построить с использованием более комплексных алгоритмов обучения с учителем.
Вывод
киль платформа для анализа данных — хороший ресурс как для исследовательских, так и для образовательных целей. Его простой в использовании графический пользовательский интерфейс помогает пользователям лучше понять требования к данным, а также предоставляет логические ссылки на полезные методы и алгоритмы, которые дополнительно помогают пользователям в их рабочих процессах. Наличие широкого спектра различных алгоритмов, подпадающих под разные категории, и алгоритмических методов позволяет пользователям экспериментировать с многочисленными логическими направлениями и сравнивать эти результаты, чтобы найти наиболее оптимальное решение любой проблемы.
Подход Keel к интеллектуальному анализу данных без перетаскивания кода помогает даже новичкам без особых усилий работать с комплексными моделями вычислительного интеллекта. Это обеспечивает понимание сложных наборов данных и, в результате, делает полезные выводы, которые помогают решать проблемы реального мира.