Давайте теперь посмотрим на утилиту iconv Linux в ее терминальной консоли. Итак, мы выполнили инструкцию «icon» с флагом «-l», чтобы отобразить все известные и наиболее часто используемые кодировки на экране нашего терминала. Он отобразит закодированные наборы символов вместе с их псевдонимами. Вы можете увидеть длинный список кодированных наборов символов после небольшой прокрутки вниз.
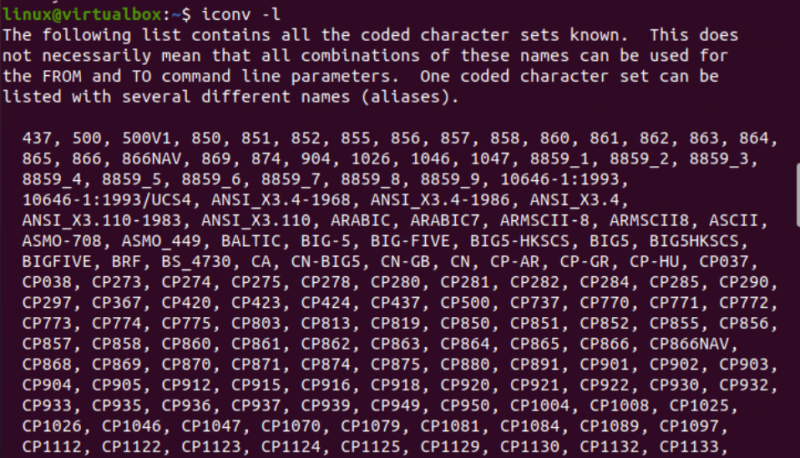
Теперь пришло время приступить к реализации команды iconv в Linux. Во-первых, нам нужны разные типы файлов в нашей системе для преобразования одного типа файла в другой тип. Таким образом, мы используем «сенсорный» запрос на консольном терминале для создания трех разных файлов, то есть типа Java, типа C и текстового типа. Перечислив текущее содержимое каталога, вы найдете в нем только что созданные файлы.
После этого мы рассмотрим тип каждого файла отдельно, используя запрос «файл» вместе с именем каждого файла. В этом запросе требуется опция «-I», чтобы отобразить тип набора символов кодирования для каждого файла отдельно. Если вы забыли использовать опцию «-I», используйте вместо нее флаг «—mime». Флаги «-I» и «—mime» работают одинаково.
Теперь, после выполнения инструкции «file» для файла типа «txt», мы получили кодировку типа символов «US-ASCII». При использовании одной и той же инструкции для файлов Java и C видно, что оба файла содержат кодировку типа «BINARY». Вместе с тем данная инструкция показывает, что все эти три файла пусты.
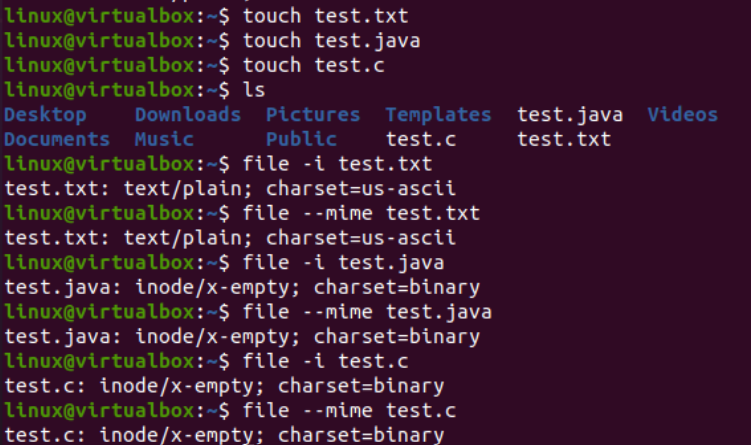
Теперь мы проиллюстрируем использование инструкции iconv на консоли для преобразования определенного файла кодировки набора символов в кодировку другого набора символов. Перед этим мы должны добавить некоторый код или данные в наши файлы. Поэтому мы добавили код Java в файл «text.java», код C в файл «text.c» и добавили текстовые данные в файл «test.txt». Запрос cat использовался здесь для отображения содержимого всех трех файлов, как показано ниже:
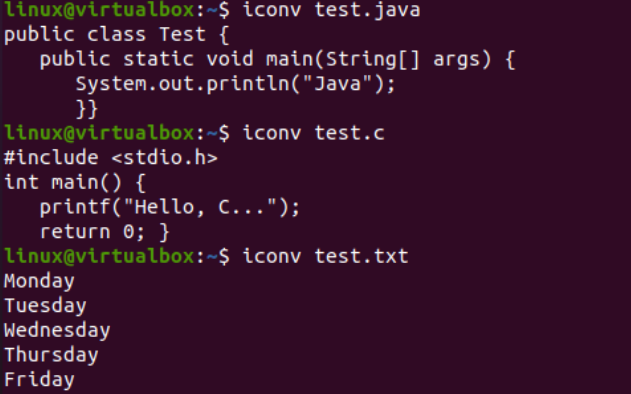
Теперь, когда мы успешно добавили данные, мы снова увидим кодировку набора символов этих файлов. Итак, мы попробовали ту же самую файловую инструкцию в оболочке с флагом «-I» и именами файлов, т. е. test.txt, test.java и test.c. Выполнение этих трех инструкций отдельно для всех трех файлов показывает, что кодировка набора символов была обновлена для файлов Java и C, но осталась прежней для текстового файла, то есть US-ASCII. Кодировка файлов Java и C ранее была «бинарной»; теперь это «US-ASCII». Кроме того, он показывает, что текстовый файл содержит простые текстовые данные, в то время как два других файла кода содержат скрипты в качестве содержимого.

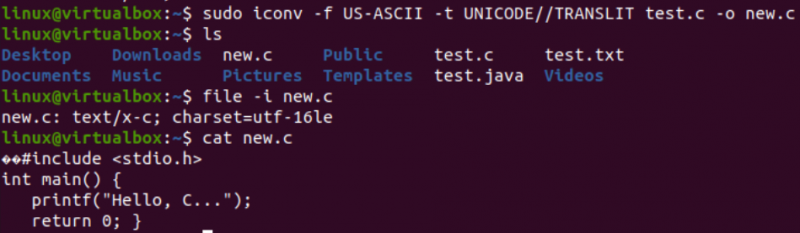
Пришло время выполнить актуальную задачу, необходимую для этой статьи, то есть преобразовать одну кодировку в другую с помощью команды iconv в оболочке. Таким образом, мы использовали инструкцию «icon» в терминале оболочки с привилегиями «sudo». Эта команда использует опцию «-f» для «от», а опцию «-t» для «до», т. е. от одной кодировки к другой.
После параметра «-f» вы должны указать кодировку, которая уже есть в вашем файле, то есть US-ASCII. В то время как после опции «-t» вы должны указать кодировку, которую хотите заменить старой кодировкой, то есть UNICODE. Вы должны указать имя файла, используемого в качестве источника, с опцией –o, чтобы создать его образ объекта. Образ объекта будет другим файлом, т. е. «new.c», того же типа, но с новой кодировкой и теми же данными.
После выполнения следующей инструкции вы получите новый файл в том же каталоге, т. е. по запросу «ls». Теперь мы проверим кодировку набора символов нового файла, сгенерированного с помощью инструкции iconv. Мы снова воспользуемся инструкцией «файл» с опцией «-I» и новым именем файла, т. е. new.c.
Вы увидите, что набор символов для этого нового файла отличается от набора символов старого файла, то есть набора символов UTF-16LE. Это связано с тем, что мы перевели кодировку US-ASCII в кодировку UNICODE с помощью инструкции iconv для нашего файла new.c. Запрос «cat» отображал тот же код C в файле, но начинался с некоторых символов Unicode, как уже было представлено.
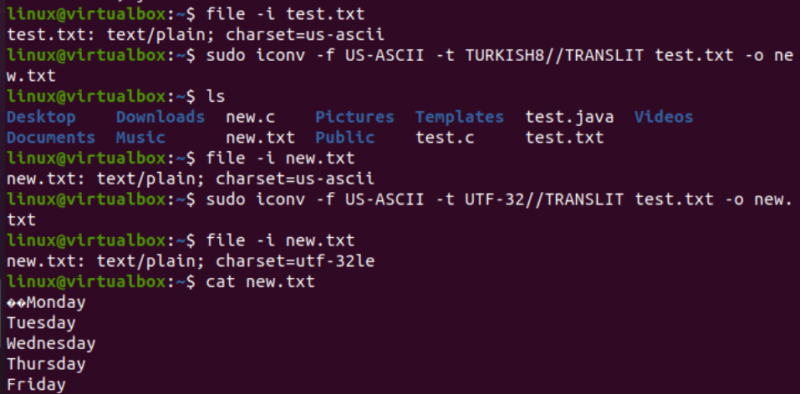
Очень похожим образом мы изменим кодировку текстового файла test.txt. Инструкция к файлу показывает, что он имеет кодировку набора символов US-ASCII. Команда iconv использовалась в том же формате для преобразования кодировки файла test.txt из US-ASCII в TURKISH8. Вы увидите, что это не меняет US-ASCII на турецкий.
После этого мы использовали ту же команду, чтобы перекрыть кодировку набора символов US-ASCII в UTF-32 для того же файла. На этот раз это работает. Это связано с тем, что иногда может возникнуть проблема с преобразованием одного набора кодировок в другой, или другая кодировка может его не поддерживать.
Вывод
В этой статье обсуждалось, как использовать инструкции iconv Linux для преобразования одного набора символов кодировки в другой, используя их псевдонимы. Таким образом, нам пришлось создать несколько файлов разных типов.