Панды заполняют значения NaN
Если столбец в вашем фрейме данных имеет значения NaN или None, вы можете использовать функции «fillna()» или «replace()», чтобы заполнить их нулем (0).
наполнять()
Значения NA/NaN заполняются предоставленным подходом с использованием функции fillna(). Его можно использовать, рассмотрев следующий синтаксис:
Если вы хотите заполнить значения NaN для одного столбца, используйте следующий синтаксис:

Когда вам необходимо заполнить значения NaN для полного кадра данных, синтаксис следующий:

Заменять()
Для замены одного столбца значений NaN предоставляется следующий синтаксис:

Принимая во внимание, что для замены значений NaN всего DataFrame мы должны использовать следующий упомянутый синтаксис:

В этой части письма мы теперь рассмотрим и изучим практическую реализацию обоих этих методов для заполнения значений NaN в нашем DataFrame Pandas.
Пример 1. Заполнение значений NaN с использованием метода Pandas «Fillna()»
На этой иллюстрации показано применение функции Pandas «DataFrame.fillna()» для заполнения значений NaN в данном DataFrame 0. Вы можете заполнить отсутствующие значения в одном столбце или заполнить их для всего DataFrame. Здесь мы увидим обе эти техники.
Чтобы применить эти стратегии на практике, нам нужно получить подходящую платформу для выполнения программы. Итак, мы решили использовать инструмент «Spyder». Мы начали наш код Python, импортировав в программу инструментарий «pandas», потому что нам нужно использовать функцию Pandas для создания DataFrame, а также для заполнения отсутствующих значений в этом DataFrame. «pd» используется как псевдоним «pandas» во всей программе.
Теперь у нас есть доступ к функциям Pandas. Сначала мы используем его функцию «pd.DataFrame()» для создания нашего DataFrame. Мы вызвали этот метод и инициализировали его тремя столбцами. Названия этих столбцов «M1», «M2» и «M3». Значения в столбце «M1»: «1», «Нет», «5», «9» и «3». Записи в «M2»: «Нет», «3», «8», «4» и «6». В то время как «M3» хранит данные как «1», «2», «3», «5» и «Нет». Нам требуется объект DataFrame, в котором мы можем хранить этот DataFrame при вызове метода «pd.DataFrame()». Мы создали «отсутствующий» объект DataFrame и присвоили ему результат, который мы получили от функции «pd.DataFrame()». Затем мы использовали метод Python «print ()» для отображения DataFrame на консоли Python.
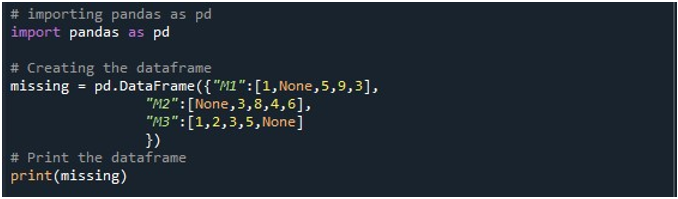
Когда мы запускаем этот фрагмент кода, на терминале можно просмотреть DataFrame с тремя столбцами. Здесь мы можем заметить, что все три столбца содержат нулевые значения.
Мы создали DataFrame с некоторыми нулевыми значениями, чтобы применить функцию Pandas «fillna ()», чтобы заполнить пропущенные значения 0. Давайте узнаем, как мы можем это сделать.
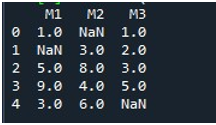
После отображения DataFrame мы вызвали функцию Pandas «fillna ()». Здесь мы научимся заполнять пропущенные значения в одном столбце. Синтаксис для этого уже упоминался в начале руководства. Мы предоставили имя DataFrame и указали заголовок конкретного столбца с помощью функции «.fillna ()». В скобках этого метода мы указали значение, которое будет помещено в пустые места. Имя DataFrame «отсутствует», а столбец, который мы выбрали здесь, — «M2». Значение, указанное между фигурными скобками «fillna()», равно «0». Наконец, мы вызвали функцию «print()» для просмотра обновленного DataFrame.

Здесь вы можете видеть, что столбец «M2» DataFrame теперь не содержит отсутствующих значений, потому что значение NaN заполнено 0.
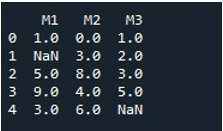
Чтобы заполнить значения NaN для всего DataFrame тем же методом, мы вызвали «fillna()». Это довольно просто. Мы предоставили имя DataFrame с функцией fillna () и присвоили значение функции «0» в скобках. Наконец, функция «print()» показала нам заполненный DataFrame.

Это дает нам DataFrame без значений NaN, так как все значения теперь заполнены 0.
Пример 2. Заполнение значений NaN с помощью метода Pandas «Replace()»
В этой части статьи демонстрируется другой метод заполнения значений NaN в DataFrame. Мы будем использовать функцию «заменить ()» Pandas для заполнения значений в одном столбце и в полном фрейме данных.
Начинаем писать код в инструменте «Spyder». Во-первых, мы импортировали необходимые библиотеки. Здесь мы загрузили библиотеку Pandas, чтобы программа Python могла использовать методы Pandas. Вторая библиотека, которую мы загрузили, — это NumPy, псевдоним «np». NumPy обрабатывает отсутствующие данные с помощью метода replace().
Затем мы создали DataFrame с тремя столбцами — «шуруп», «гвоздь» и «сверло». Значения в каждом столбце даны соответственно. Столбец «винт» имеет значения «112», «234», «Нет» и «650». В столбце «гвоздь» есть «123», «145», «Нет» и «711». Наконец, столбец «сверло» имеет значения «312», «Нет», «500» и «Нет». DataFrame хранится в объекте DataFrame «tool» и отображается с помощью метода «print()».
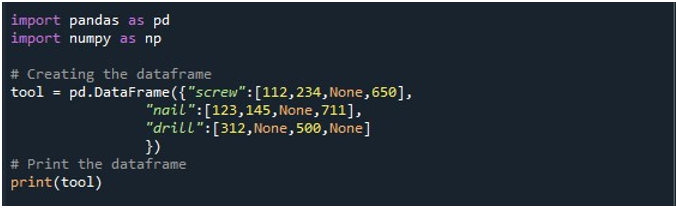
Кадр данных с четырьмя значениями NaN в записи можно увидеть на следующем выходном изображении:
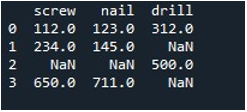
Теперь мы используем метод «заменить ()» Pandas для заполнения нулевых значений в одном столбце DataFrame. Для задачи мы вызвали функцию «replace()». Мы предоставили имя DataFrame «tool» и столбец «screw» с помощью метода «.replace ()». Между фигурными скобками мы устанавливаем значение «0» для записей «np.nan» в DataFrame. Метод «print()» используется для отображения вывода.

Результирующий DataFrame показывает нам первый столбец с заменой записей NaN на 0 в столбце «винт».
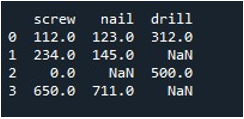
Теперь мы научимся заполнять значения во всем DataFrame. Мы вызвали метод «заменить ()» с именем DataFrame и предоставили значение, которое мы хотим заменить записями np.nan. Наконец, мы напечатали обновленный DataFrame с помощью функции «print()».

Это дает нам результирующий DataFrame без пропущенных записей.
Вывод
Работа с отсутствующими записями в DataFrame является фундаментальным и необходимым требованием для снижения сложности и вызывающей обработки данных в процессе анализа данных. Pandas предоставляет нам несколько вариантов решения этой проблемы. В этом руководстве мы представили две удобные стратегии. Мы применяем на практике оба метода с помощью инструмента «Spyder» для выполнения примеров кода, чтобы вам было немного понятно и проще. Получение знаний об этих функциях улучшит ваши навыки Pandas.