Как использовать заявление Pandas?
Операторы case могут быть созданы несколькими способами. Функция NumPy where(), использующая следующий фундаментальный синтаксис, является самым простым способом создания оператора case в Pandas DataFrame:
дф [ «имя столбца» ] = np.где ( условие 1 , «значение1»,нп.где ( условие два , «значение2»,
нп.где ( условие 3 , «значение3», «значение4» ) ) )
Приведенный выше оператор проверит каждое условие на наличие значения и, если условие выполнено, сгенерирует вывод или вернет значение в соответствии с условием.
Пример # 1: оператор Case Pandas с использованием функции where ()
Давайте сначала создадим фрейм данных, чтобы мы могли использовать наш оператор case. Чтобы создать фрейм данных, мы сначала импортируем модули numpy и pandas, чтобы мы могли использовать их функциональные возможности. pd.Dataframe() будет использоваться для создания нашего фрейма данных.

Мы создали фрейм данных «df». Словарь Python передается внутри функций pd.DataFrame() в качестве аргумента с ключами и значениями. Мы будем использовать функцию print(), чтобы увидеть наш фрейм данных.
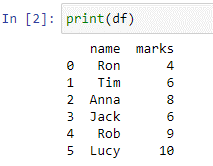
Во фрейме данных «df» у нас есть два столбца «имя» и «метки» со значениями [«Рон», «Тим», «Анна», «Джек», «Роб», «Люси»] и [4, 6 , 8, 6, 9,10] соответственно. Предположим, что имя — это столбцы, в которых хранятся имена студентов, а столбец «оценки» хранит результаты какого-то недавнего теста. Теперь мы напишем оператор case, который добавляет новый столбец с именем «замечания», значения которого основаны на значениях, указанных нами для каждого условия.

Метод «numpy.where ()» предоставляет индексы элементов из входного массива, столбца или списка, которые удовлетворяют указанному условию. В приведенном выше случае переключения функция np.where() проверяет каждый элемент в столбцах «метки». Если значение равно или меньше 5, в качестве вывода будет возвращено «сбой». Если значение меньше или равно 7, будет возвращено удовлетворительное, а если значение меньше или равно 9, будет возвращено «отлично». Если их нет, результат будет отличным.
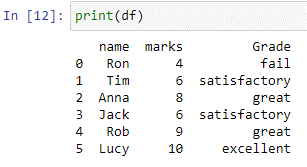
Как можно заметить, новый столбец «примечания» создается в нашем фрейме данных «df», в котором хранятся значения, возвращаемые приведенным выше оператором case.
Пример №2:
Давайте снова попробуем приведенный выше оператор case с другим фреймом данных. Предположим, нам нужно оценить игроков на основе их общего количества голов в предыдущем футбольном турнире. Итак, давайте создадим фрейм данных для хранения записей футболистов.
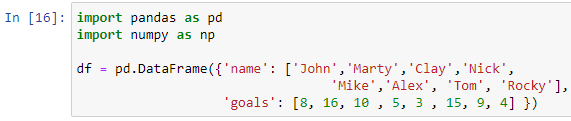
Мы передали словарь с ключами «имя» и «цели» внутри функции pd.DataFrame() для создания нашего фрейма данных. Чтобы распечатать наш фрейм данных, мы будем использовать функцию печати.
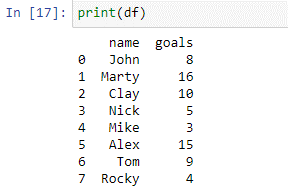
Как видно из приведенного выше фрейма данных, у нас есть два столбца: «имя» и «цели». В названии столбца у нас есть имена игроков [«Джон», «Марти», «Клэй», «Ник», «Майк», «Алекс», «Том», «Рокки»]. В «столбце» целей у нас есть общее количество голов, забитых каждым игроком в предыдущем турнире. Теперь мы воспользуемся нашим случаем, чтобы оценить этих игроков на основе забитых ими голов.

Приведенный выше случай создается с использованием функции where(). Внутри кейса функция-оператор проверяет каждый элемент в столбцах «метки» на соответствие условиям. Если значение в столбце «Цели» равно или меньше 5, возвращается «C». Если значение в столбце «Цели» равно или меньше 9, будет возвращено «В». Он вернет «A», если значение в столбце «цели» равно или больше 10. Значения, возвращаемые оператором, будут сохранены в новом столбце «рейтинг». Давайте напечатаем «df», чтобы увидеть результаты.
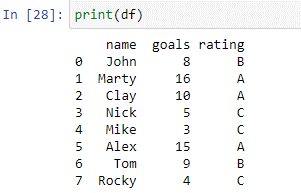
Новый столбец «рейтинг» успешно создан с помощью приведенного выше скрипта.
Пример № 3: оператор Pandas if-else с использованием функции apply()
Ось строки или столбца фрейма данных используется методом apply() для реализации функции. Мы можем создать нашу собственную определенную функцию и использовать ее в нашем фрейме данных в pandas. Он будет содержать условия if-else. Давайте сначала создадим наш фрейм данных, затем мы создадим функцию, в которой мы будем использовать оператор if-else для генерации результата. Чтобы создать наш фрейм данных, мы сначала импортируем модуль pandas, а затем передадим словарь в метод pd.DataFrame().
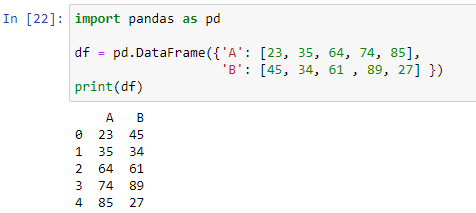
Как видно, наш фрейм данных состоит из двух столбцов «A», в которых хранятся числовые значения [23, 35, 64, 74, 85], и «B» со значениями [45, 34, 61, 89, 27]. Теперь мы создадим функцию, которая будет определять, какое значение больше среди обоих столбцов в каждой строке нашего фрейма данных.
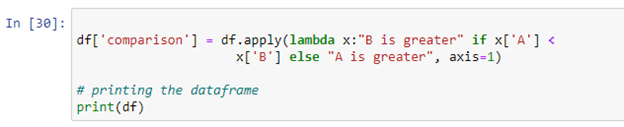
Вы можете использовать лямбда-функцию Python «pandas. DataFrame.apply()», чтобы запустить выражение. В Python лямбда-функция — это компактная анонимная функция, которая принимает любое количество аргументов и выполняет выражение. В приведенном выше сценарии мы создали оператор условия, который будет сравнивать значения обоих столбцов и сохранять результат в новом столбце «сравнение». Если значение столбца «A» меньше значения столбца «B», он вернет «B больше». Если условие не выполняется, возвращается «A больше».
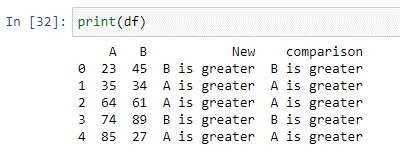
Пример №4:
Давайте попробуем другой пример, используя оператор if-else внутри функции apply() с другим фреймом данных.
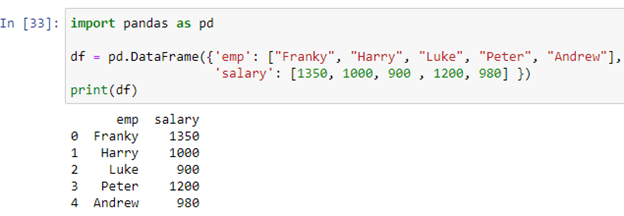
Предположим, наш фрейм данных хранит записи о сотрудниках какой-то компании. В столбце «emp» хранятся имена сотрудников [«Фрэнки», «Гарри», «Люк», «Питер», «Эндрю»], тогда как в столбце «Зарплата» хранится заработная плата каждого сотрудника [1350, 1000, 900 , 1200, 980] во фрейме данных 'df'. Теперь мы создадим наш оператор if-else, используя метод apply().

Приведенное выше условие проверяет каждое значение в столбце «зарплата» и добавляет 200 к зарплате сотрудников, у которых значение зарплаты меньше или равно 1000. Мы сохранили значения, возвращенные функцией apply(), в новом столбце « приращение'. Давайте посмотрим на результаты приведенного выше скрипта.
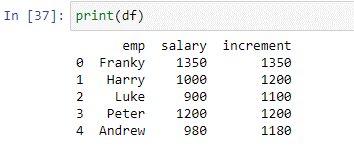
Как видите, функция успешно добавила 200 к значениям, которые были меньше или равны 100. Значения, которые были больше 1000, остались без изменений.
Вывод:
В этом руководстве мы видели, что когда условие выполняется, оператор этого типа, называемый оператором case, возвращает значение. Мы увидели, как можно создать оператор case для выполнения требуемой операции или задачи. В этом руководстве мы использовали функцию np.where() и функцию apply() для создания операторов case. Мы реализовали несколько примеров, чтобы научить вас, как использовать операторы case в pandas с помощью функции where() и как использовать функцию apply() для создания операторов case.