В этой статье мы рассмотрим важность структуры данных , различные виды структуры данных доступны в C++, и как эффективно использовать их в своих программах.
Что такое структура данных в C++
структура данных является важным понятием в программировании и играет жизненно важную роль в хранении и организации данных. В C++ структуру данных можно определить как способ хранения данных и управления данными в определенном формате. Это обеспечивает эффективный доступ к данным и управление ими, облегчая программистам написание и поддержку кода.
В С++, структуры данных иметь следующий синтаксис:
структура имя_структуры {
тип данных1 имя1 ;
тип данных2 имя2 ;
тип данных3 имя3 ;
тип данных4 имя4 ;
..
..
..
} obj_name ;
В приведенном выше синтаксисе ключевое слово структура используется для определения структуры и имя_структуры — определяемое пользователем имя структуры, которое может варьироваться. тип данных1 является типом данных члена структуры и имя1 имя члена структуры и obj_name имя объекта, для которого определена структура.
Пример
В приведенном ниже примере Информация о структуре состоит из трех членов: Назовите возраст, и гражданство.
структура Информация
{
уголь имя [ пятьдесят ] ;
инт гражданство ;
инт возраст ;
}
Давайте запустим этот код на C++, мы определили все эти члены в структуре person и не выделили места. В основной функции мы инициализировали эти элементы определенными значениями и распечатали их:
#include <иопоток>используя пространство имен std ;
структура Информация
{
имя строки ;
инт возраст ;
} ;
инт основной ( пустота ) {
структура Информация р ;
п. имя '=' 'Зайнаб' ;
п. возраст '=' 23 ;
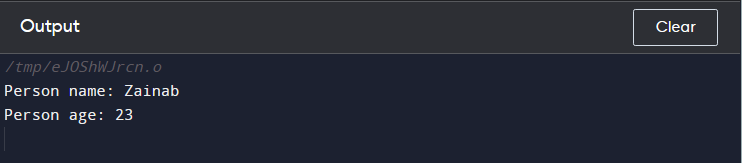
cout << 'Имя человека:' << п. имя << конец ;
cout << «Возраст человека:» << п. возраст << конец ;
возвращаться 0 ;
}
Код определяет структуру с именем Информация с двумя атрибутами: имя и возраст. В основной функции появился новый Информация объект создается и ему присваивается имя и возраст. Наконец, значения этих полей выводятся на консоль с помощью cout.
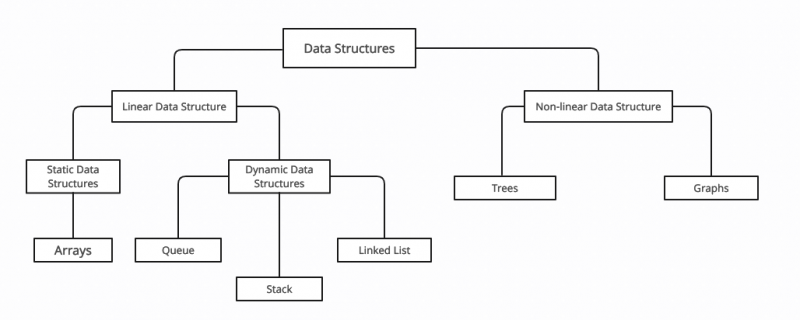
Классификация структуры данных в C++
В С++ структура данных делится на две большие категории: Линейные и нелинейные структуры данных . Структуры данных делятся на основе следующих характеристик:
| Характеристика | Объяснение | Пример |
| Линейный | Данные располагаются в линейной последовательности | Массивы |
| Нелинейный | Элементы данных не находятся в линейной последовательности | График, Дерево |
| Статический | Расположение, размер и память фиксированы | Массивы |
| Динамический | Размер меняется в зависимости от исполнения программы | Связанный список |
| Однородный | Предметы одного типа | Массивы |
| Неоднородный | Элементы могут быть или не быть одного и того же типа | Структуры |
Категории структур данных в C++:
1: Массивы
Массивы являются наиболее фундаментальными структурами данных C++. Массив — это группа элементов с одинаковым типом данных. Массивы упрощают выполнение операций над всем набором данных. Значения, хранящиеся в массивах, называются элементами.
2: связанный список
Элементы данных в связанном списке связаны через узлы. Каждый узел имеет адрес и данные узла после него. Они лучше всего подходят для добавления и удаления узлов. Связанные списки бывают двух типов: односвязные и двусвязные списки. В односвязном списке предыдущий узел имеет данные узла после него, но следующий узел не знает о предыдущем узле. В двусвязном списке направление как вперед, так и назад.
3: Стеки
Стеки — это абстрактный тип данных, который следует принципу LIFO (Last in First Out). Это правило означает, что элемент, вставленный последним, будет удален первым. Они используются с рекурсивными алгоритмами поиска с возвратом.
4: Хвосты
Очереди также являются абстрактным типом данных и следуют правилу FIFO (First In and First Out). Это правило означает, что элемент, вставленный первым, будет удален первым. Они полезны при обработке системных интерпретаций в реальном времени.
5: Деревья
Деревья представляют собой набор нелинейных структур данных с несколькими узлами. Он допускает только одно ребро с двумя вершинами.
6: Графики
В графе каждый узел является вершиной, и каждая вершина связана с другой вершиной через ребро. Сферы — это вершины, а стрелки — ребра, они используются для реализации реальных сценариев или нейронных сетей. Графы бывают трех разных типов: неориентированный граф, двунаправленный граф и взвешенный граф.
Операции, выполняемые над структурами данных
Мы можем выполнять следующие функции над структурами данных в C++:
- Вставка новых элементов данных в структуры данных.
- Удаление существующих элементов данных из структуры данных.
- Отобразите все элементы данных в структуре данных.
- Поиск определенного элемента в структуре данных.
- Расположите все элементы в порядке возрастания или убывания.
- Объедините элементы из двух структур данных и создайте новую.
Нижняя граница
Структуры данных в C++ — это способ эффективной обработки данных, чтобы к ним можно было получить доступ. Важно выбрать подходящую структуру данных для вашего проекта, если вы хотите добавлять данные последовательно, используйте массивы. Понимание концепции структуры данных поможет вам овладеть искусством программирования и разработки алгоритмов.