Иногда данный набор данных находится не в одном файле CSV. Все они находятся на разных листах Excel. Вы уже знаете, что предпочтительнее выполнять все вычислительные действия или действия по предварительной обработке с одним набором данных, а не с несколькими наборами данных. Это сокращает или экономит время, которое нам нужно потратить на задачи предварительной обработки. Кроме того, как аналитик данных или специалист по данным, вы часто можете оказаться перегруженными многочисленными файлами CSV, которые необходимо объединить, прежде чем вы даже начнете анализ или изучение доступных данных. С другой стороны, не всегда возможно, чтобы все файлы были получены из одного или одного источника данных и имели одинаковые имена столбцов/переменных и структуру данных. Этот пост научит вас объединять два или более CSV-файла с одинаковой или разной структурой столбцов.
Зачем объединять файлы CSV?
Набор данных может представлять собой набор или группу значений или чисел, относящихся к определенной теме. Например, результаты тестов каждого учащегося в определенном классе являются примером набора данных. Из-за размера больших наборов данных они часто хранятся в отдельных файлах CSV для разных категорий. Например, если нам необходимо обследовать пациента на наличие определенного заболевания, мы должны учитывать каждый компонент, включая его пол, историю болезни, возраст, тяжесть заболевания и т. д. Следовательно, для изучения различных факторов, влияющих на предикторы, требуется объединение данных CSV. аспекты. Кроме того, при выполнении вычислений или задач предварительной обработки лучше работать и управлять одним набором данных, а не несколькими наборами данных. Экономит память и другие вычислительные ресурсы.
Как объединить файлы CSV в Python?
Существует несколько способов и методов объединения двух или более файлов CSV в Python. В разделе ниже мы будем использовать функции append(), concat() и merge() и т. д. для объединения файлов CSV в кадр данных pandas, после чего кадры данных будут преобразованы в один файл CSV. Мы научим, как объединить несколько файлов CSV с одинаковой или переменной структурой столбцов.
Способ №1: объединение CSV с похожими структурами или столбцами
В нашем текущем рабочем каталоге есть два файла CSV: «test1» и «test2».
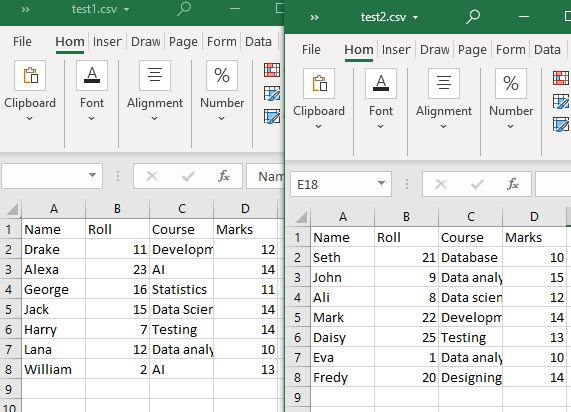
Пример № 1: Использование функции append()
Оба файла CSV имеют одинаковую структуру. Функция glob() будет использоваться в этом методе только для отображения CSV-файлов в рабочем каталоге. Затем мы будем использовать «pandas.DataFrame.append()» для чтения наших файлов CSV (с общей структурой таблицы).

Выход:
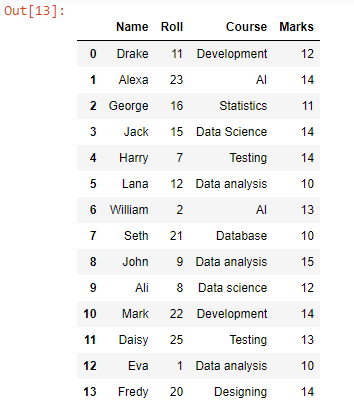
Используя функцию добавления, мы добавили или добавили каждую строку данных из test2.csv под строками данных test1.csv, поскольку видно, что все строки данных файла были объединены. Чтобы преобразовать этот кадр данных в CSV, мы можем использовать функцию to_csv().

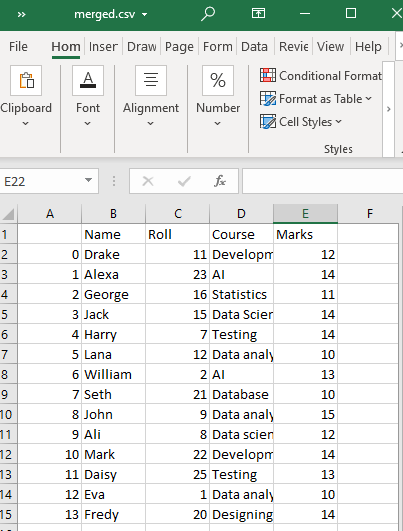
Это создаст объединенный CSV-файл из CSV-файлов «test1» и «test2» в нашем рабочем каталоге с указанным именем, т. е. merged.csv.
Пример № 2: Использование функции concat()
Сначала мы импортируем модуль pandas. Метод карты будет читать каждый файл CSV, который мы передали, используя pd.read_csv(). Эти сопоставленные файлы (CSV-файлы) затем будут объединены по оси строк по умолчанию с помощью функции pd.concat(). Если мы хотим объединить файлы CSV по горизонтали, мы можем передать axis=1. Указание индекса игнорирования = True также создает непрерывные значения индекса для объединенного фрейма данных.

pd.read_csv() передается внутри функции concat() для чтения CSV-файлов в кадр данных pandas после конкатенации.
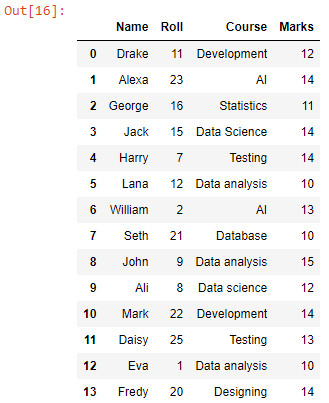
Мы получили кадр данных с объединенными данными всех файлов CSV в рабочем каталоге. Теперь давайте конвертируем его в файл CSV.
Наш объединенный CSV создается в текущем каталоге.
Способ №2: объединение CSV с разными структурами или столбцами
Мы обсуждали объединение файлов CSV с одинаковыми столбцами и структурой в первом методе. В этом методе мы будем комбинировать файлы CSV с разными столбцами и структурами.
Пример № 1: Использование функции merge()
Функция pandas.merge() в модуле pandas может объединять два файла CSV. Слияние просто означает объединение двух наборов данных в один набор данных на основе общих столбцов или атрибутов.
Мы можем объединить кадры данных четырьмя различными способами:
- Внутренний
- Верно
- Оставил
- Внешний
Для выполнения этих типов слияний мы будем использовать два файла CSV.
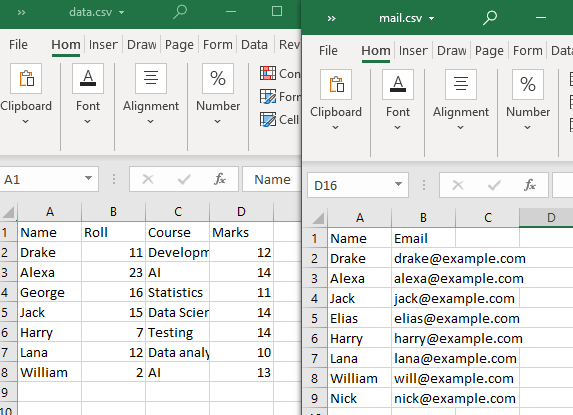
Обратите внимание, что по крайней мере один атрибут или столбец должны быть общими для обоих CSV-файлов. Как видно, столбец «Имя» и некоторые его атрибуты являются общими для обоих CSV-файлов.
Слияние с использованием внутреннего соединения
Указание параметра how=’inner’ в функции merge() объединит два фрейма данных в соответствии с указанным столбцом, а затем предоставит новый фрейм данных, который содержит только строки с идентичными/одинаковыми значениями в обоих исходных фреймах данных.
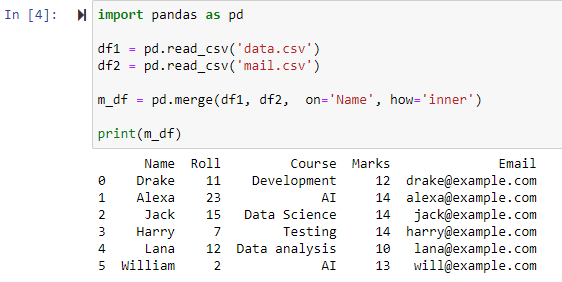
Как видно, функция объединила оба CSV-файла и вернула строки на основе общих атрибутов столбца «Имя».
Слияние с использованием правого внешнего соединения
Когда указан параметр how=’right’, оба фрейма данных будут объединены на основе столбца, который мы указали для параметра ‘on’. И будет возвращен новый фрейм данных, содержащий все строки из правого фрейма данных, включая любые строки, для которых левый фрейм данных не содержит значений, со значением столбца левого фрейма данных, установленным в NAN.
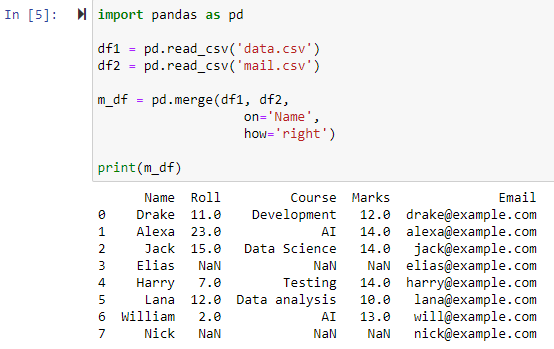
Слияние с использованием левого внешнего соединения
Когда параметр указан как «левый», два фрейма данных будут объединены на основе указанного столбца с использованием параметра «on», возвращая новый фрейм данных, который содержит все строки из левого фрейма данных, а также любые строки, которые имеют NAN или нулевые значения в правом фрейме данных и устанавливает значение столбца правого фрейма данных в NAN.
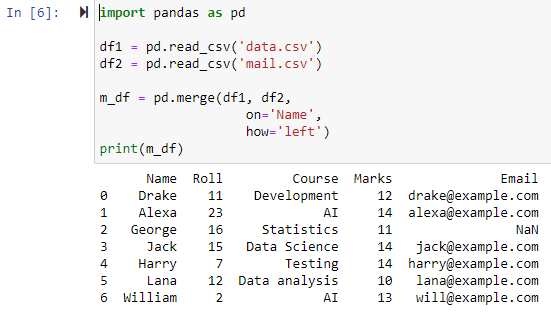
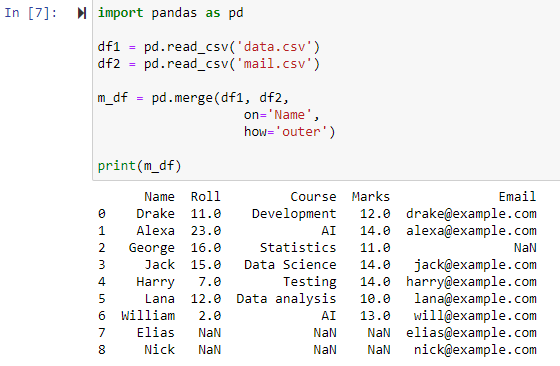
Слияние с использованием полного внешнего соединения
Когда указано как = 'outer', два фрейма данных будут объединены в зависимости от столбца, указанного для параметра on, возвращая новый фрейм данных, содержащий строки из фреймов данных df1 и df2, и устанавливая NAN в качестве значения для любых строк. для которых данные отсутствуют в одном из фреймов данных.
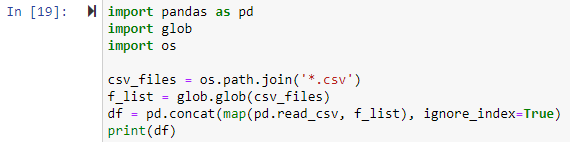
Пример № 2: Объединение всех CSV-файлов в рабочем каталоге
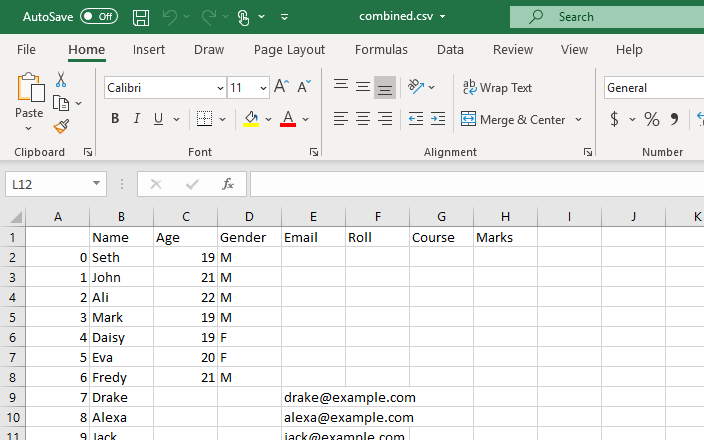
В этом методе мы будем использовать модуль glob для объединения всех файлов .csv в кадр данных pandas. Сначала нужно было импортировать все библиотеки. Далее мы укажем путь для каждого файла CSV, который мы хотим объединить. Путь к файлу — это первый аргумент функции os.path.join() в приведенном ниже примере, а второй аргумент — либо компоненты пути, либо файлы .csv, которые необходимо объединить. Здесь выражение *.csv найдет и вернет каждый файл в рабочем каталоге, который заканчивается расширением файла .csv. Функция glob.glob(filesjoined) принимает список имен объединенных файлов в качестве входных данных и выводит список всех объединенных/объединенных файлов.
Этот скрипт вернет кадр данных с объединенными данными всех файлов CSV в нашем рабочем каталоге.
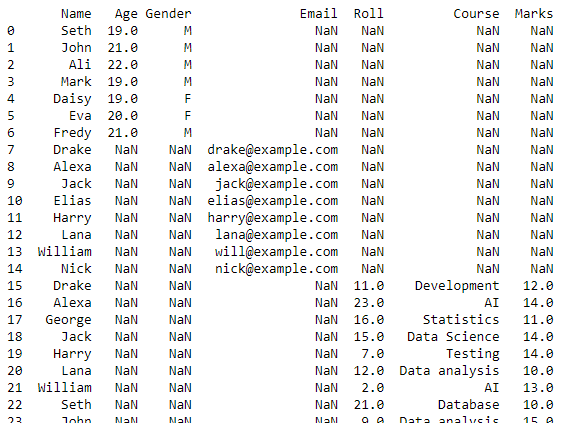
Этот кадр данных будет преобразован в файл CSV, и для этого преобразования будет использоваться функция to_csv(). Этот новый CSV-файл будет представлять собой объединенные CSV-файлы, созданные из всех CSV-файлов, хранящихся в текущем рабочем каталоге.
Вывод
В этом посте мы обсудили, почему нам нужно объединять файлы CSV. Мы обсудили, как в Python можно объединить два или более CSV-файла. Мы разделили этот учебник на две части. В первом разделе мы объяснили, как использовать функции append() и concat() для объединения CSV-файлов с одинаковой структурой или именами столбцов. Во втором разделе мы использовали метод merge(), os.path.join() и метод glob для объединения CSV-файлов с разными столбцами и структурами.