В этой статье представлены инструкции по внедрению интеллектуального многоуровневого управления для оптимизации затрат в сегменте S3.
Что такое интеллектуальное многоуровневое распределение в сегменте S3?
Данные растут в геометрической прогрессии по всему миру. Доступ к некоторым из этих данных осуществляется ежедневно, а остальные требуются лишь время от времени. Поскольку S3 является одним из самых популярных сервисов AWS для хранения данных, AWS представила класс хранения, известный как «Интеллектуальное многоуровневое распределение» сократить расходы S3 за счет хранения данных. Дополнительную информацию о различных классах хранения корзин S3 можно найти в этой статье: «Обзор различных классов хранения данных на S3» .
Intelligent-Tiering может оптимизировать расходы S3, отслеживая шаблоны доступа к данным. Эта функция достаточно эффективна, чтобы определить, к каким данным обращаются часто или время от времени. На основе этих шаблонов он автоматически идентифицирует и помещает их на наиболее экономичный уровень без каких-либо эксплуатационных затрат или снижения производительности.
Как оптимизировать затраты на хранение данных в Amazon S3 с помощью интеллектуального многоуровневого хранения?
В зависимости от шаблонов доступа к данным объекты, к которым редко обращаются, будут помещены в более дешевый уровень доступа в целях оптимальной стоимости. Если к объекту обращается пользователь, он будет автоматически и немедленно перемещен обратно в Уровень частого доступа при наличии без дополнительной оплаты:
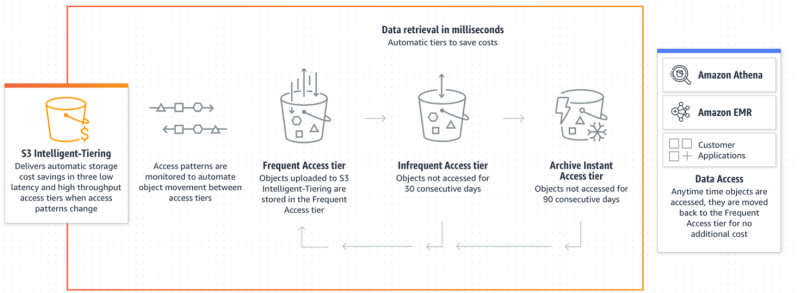
Интеллектуальное многоуровневое распределение — это осуществимый и идеальный выбор для пользователей, когда речь идет об оптимизации затрат на непредсказуемые схемы доступа к данным. Ниже приведены шаги, с помощью которых мы можем реализовать класс хранения с интеллектуальным многоуровневым хранением для обеспечения экономической эффективности:
Шаг 1: Панель управления S3
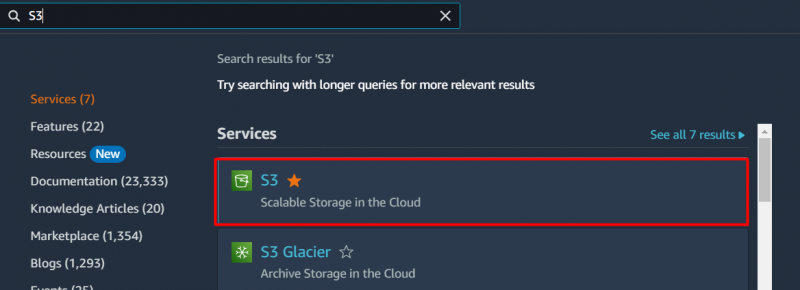
Чтобы найти оптимальное по стоимости решение для хранения данных с помощью корзины S3, найдите 'С3' сервис в строке поиска AWS и щелкните его в отображаемых результатах:
Шаг 2. Создайте сегмент
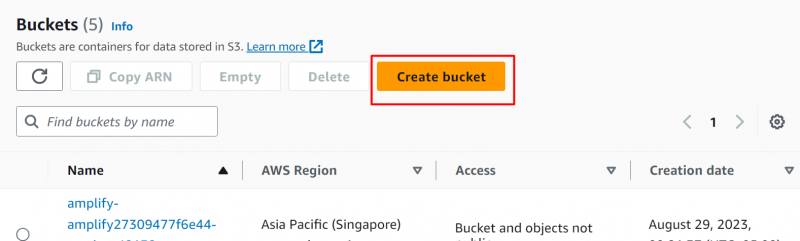
Нажать на «Создать ведро» кнопка на Консоль S3 :
Шаг 3: Общие конфигурации
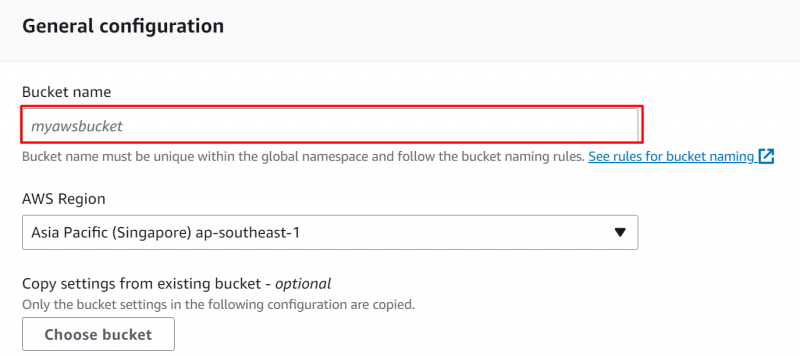
В отображаемом интерфейсе укажите уникальный идентификатор для ведра S3 в «Общие конфигурации» раздел:
Шаг 4. Нажмите кнопку «Создать корзину».
Сохранив настройки по умолчанию, нажмите кнопку «Создать ведро» кнопка, расположенная в нижней части интерфейса:
Ведро успешно создано. Далее мы загрузим файл в это ведро. Нажмите на имя корзины, чтобы перейти к интерфейсу загрузки файла:
Шаг 5: Загрузите файлы
Нажмите кнопку 'Загрузить' кнопка в отображаемом интерфейсе:
Для выбора файлов нажмите на кнопку 'Добавить файлы' кнопку, а затем выберите файлы/папки на вашем устройстве. Файл загружен в корзину S3:
Перейдите к 'Характеристики' блок и выберите « Интеллектуальное многоуровневое распределение» вариант из Класс хранилища раздел :
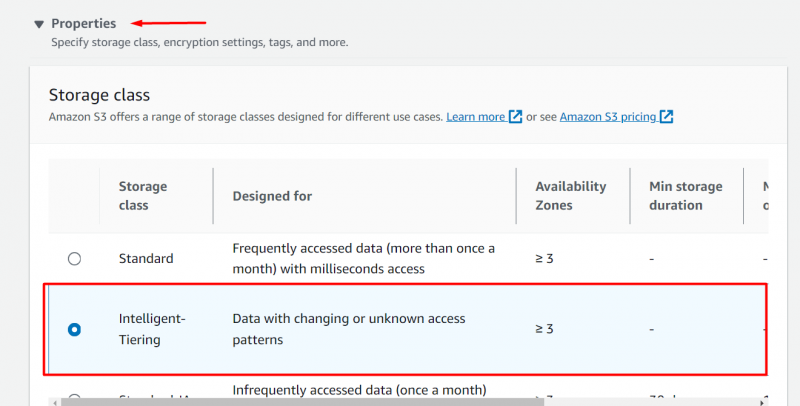
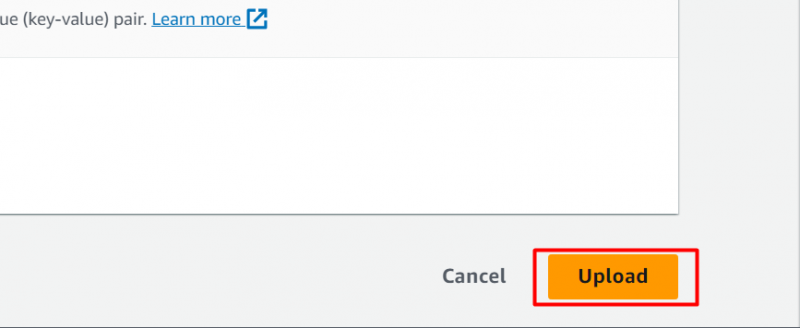
Сохраняя остальную часть настройки без изменений , нажать на 'Загрузить' кнопка, расположенная в нижней части интерфейса:
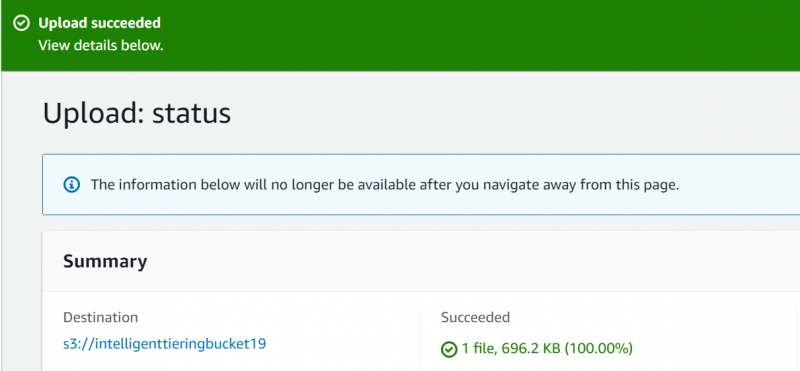
AWS отобразит подтверждающее сообщение что означает, что файл успешно загружен:
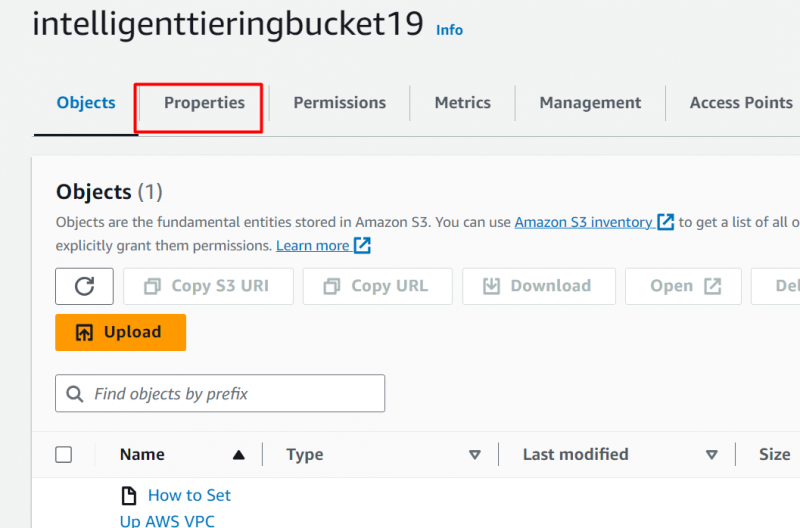
Шаг 6: Нажмите вкладку «Свойства».
После загрузки файла нажмите кнопку 'Характеристики' вкладка:
Шаг 7. Конфигурации архивов с интеллектуальным многоуровневым хранением
Из Характеристики интерфейс, прокрутите вниз до «Конфигурации интеллектуального многоуровневого архива» раздел и нажмите кнопку «Создание конфигураций» кнопка:
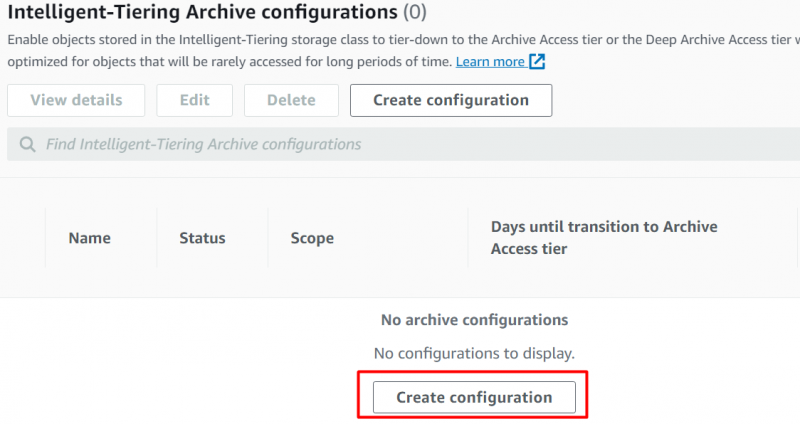
Предоставьте 'Имя' и 'Префикс' для конфигураций следующего отображаемого интерфейса:
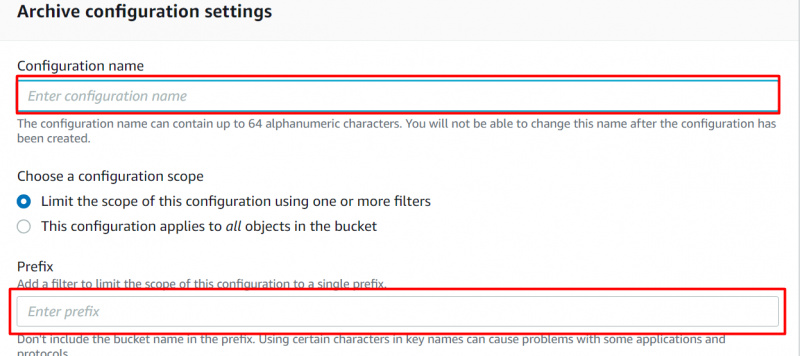
Шаг 8: Уровень доступа к архиву
Перейдите к «Действия правила архивирования» раздел для настройки того, когда объекты должны быть перемещены. Включите следующую опцию и укажите количество последовательных дней, по истечении которых вы хотите переместить объекты в «Уровень доступа к архиву» :
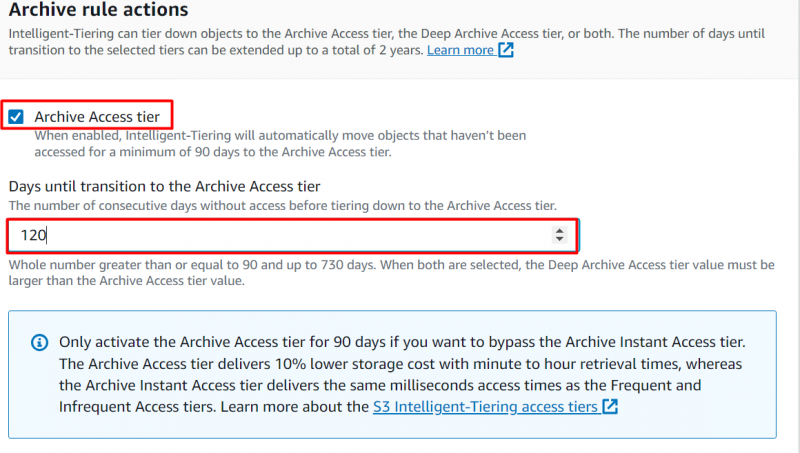
Примечание : Если к объекту не осуществляется доступ в течение как минимум 90 дней, объект будет автоматически перемещен на уровень доступа к архиву. Пользователи могут продлить этот период на максимум из 730 дней.
Шаг 9: Уровень доступа к глубокому архиву
Как и уровень доступа к архиву, пользователь также может настроить уровень доступа к глубокому архиву. Включив следующую опцию, укажите количество дней, по истечении которых объект должен быть перемещен на уровень доступа к глубокому архиву. Указав количество дней, нажмите кнопку 'Создавать' кнопка:
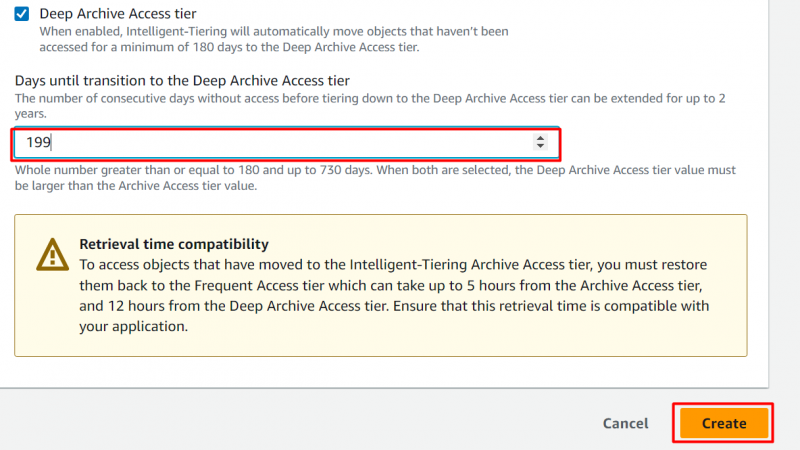
Примечание : на уровне доступа к глубокому архиву объекты, к которым не было доступа в течение минимум 180 дней перенесены на этот уровень. Пользователи могут настроить это количество дней по своему усмотрению. максимум 730 дней .
Конфигурации выполнены успешно. Теперь, когда загруженные объекты не будут доступны пользователю в течение указанного времени, данные будут автоматически перемещаться на разные уровни для минимизации затрат:
Это все из этого руководства.
Заключение
Для оптимизации затрат с помощью корзины S3 выберите вариант Интеллектуальный многоуровневый класс при загрузке файлов, а затем укажите время для соответствующих уровней. Интеллектуальное многоуровневое хранение экономит средства, распределяя часто и редко используемые объекты по соответствующим уровням. В этой статье представлены пошаговые инструкции по созданию экономически оптимального решения с помощью корзины S3.