Как администраторы баз данных, мы должны быть одержимы инструментами и методами повышения производительности базы данных.
В PostgreSQL у нас есть доступ к команде EXPLAIN ANALYZE, которая позволяет нам анализировать план выполнения и производительность данного запроса к базе данных. Команда возвращает подробную информацию о том, как ядро базы данных обрабатывает запрос. Это включает в себя последовательность выполняемых операций, предполагаемую стоимость запросов, время выполнения и многое другое.
Затем мы можем использовать эту информацию для идентификации запросов к базе данных, а также для выявления и устранения потенциальных узких мест в производительности.
В этом руководстве рассказывается, как использовать команду EXPLAIN ANALYZE в PostgreSQL для просмотра и оптимизации производительности запросов.
PostgreSQL ОБЪЯСНИТЬ АНАЛИЗ
Команда довольно проста. Во-первых, нам нужно добавить команду EXPLAIN ANALYZE в начале запроса, который мы хотим проанализировать.
Синтаксис команды следующий:
EXPLAIN ANALYZE <целевой_запрос>После выполнения команды PostgreSQL возвращает подробный вывод о предоставленном запросе.
Понимание вывода запроса EXPLAIN ANALYZE
Как уже упоминалось, после запуска команды EXPLAIN ANALYZE PostgreSQL создает подробный отчет о плане запроса и статистике выполнения.
Вывод состоит из набора столбцов, содержащих полезную информацию. Результирующие столбцы показаны с их соответствующим значением:
ПЛАН ЗАПРОСА – В этом столбце отображается план выполнения указанного запроса. План выполнения относится к последовательности операций, которые ядро базы данных выполняет для успешного завершения запроса.
ПЛАН – Второй столбец – это столбец ПЛАН. Он содержит текстовое представление каждой операции или шага в плане выполнения. Опять же, каждая операция имеет отступ, чтобы указать иерархию операций.
ОБЩАЯ СТОИМОСТЬ – Столбец общей стоимости представляет предполагаемую общую стоимость запроса. Стоимость относится к относительному показателю, который планировщик запросов к базе данных использует для определения оптимального плана выполнения.
РЕАЛЬНЫЕ РЯДЫ – В этом столбце показано точное количество строк, которые обрабатываются на каждом этапе выполнения запроса.
ФАКТИЧЕСКОЕ ВРЕМЯ – В этом столбце показано фактическое время, затраченное на каждую операцию, которое включает как время выполнения операции, так и время, затраченное на ресурсы.
ВРЕМЯ ПЛАНИРОВАНИЯ – В этом столбце показано время, которое требуется планировщику запросов для создания плана выполнения. Сюда входит общее время оптимизации запроса и генерации плана.
ВРЕМЯ ИСПОЛНЕНИЯ – В этом столбце показано общее время выполнения запроса. Это также включает время, потраченное на планирование и время выполнения запроса.
PostgreSQL EXPLAIN ANALYZE Пример
Давайте рассмотрим несколько основных примеров использования оператора EXPLAIN ANALYZE.
Пример 1: оператор выбора
Давайте воспользуемся оператором EXPLAIN ANALYZE, чтобы показать выполнение простого оператора select в PostgreSQL.
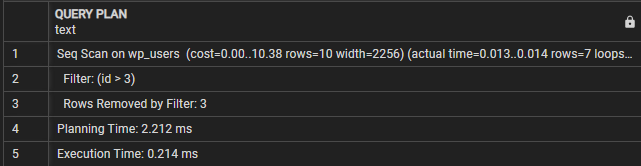
Как только мы запустим предыдущий оператор, мы должны получить следующий вывод:
ПЛАН ЗАПРОСА-------------------------------------------------- ------------------
Seq Scan на wp_users (стоимость = 0,00..10,38 строк = 10 ширина = 2256) (фактическое время = 0,009..0,010 строк = 7 циклов = 1)
Фильтр: (идентификатор > 3)
Строки, удаленные фильтром: 3
Время планирования: 0,995 мс
Время выполнения: 0,021 мс
(5 рядов)
В этом случае мы видим, что в разделе «План запроса» указано, что запрос выполняет последовательное сканирование таблицы wp_users. Строка фильтра обозначает условие, которое используется для фильтрации результирующих строк.
Затем мы видим «Строки, удаленные фильтром», в котором показано количество строк, удаленных фильтром.
Наконец, время выполнения показывает общее время выполнения запроса. В этом случае запрос занимает 0,021 мс.
Пример 2: анализ объединения
Возьмем более сложный запрос, включающий соединение SQL. Для этого мы используем образец базы данных Pagila. Вы можете загрузить и установить образец базы данных на свой компьютер для демонстрационных целей.
Мы можем запустить простое соединение, как показано ниже:
объяснить анализ ВЫБЕРИТЕ f.title, c.nameИЗ фильма ф
ПРИСОЕДИНЯЙТЕСЬ film_category fc ON f.film_id = fc.film_id
ПРИСОЕДИНЯЙТЕСЬ к категории c ON fc.category_id = c.category_id;
Как только мы запустим данный запрос, мы должны увидеть результат следующим образом:
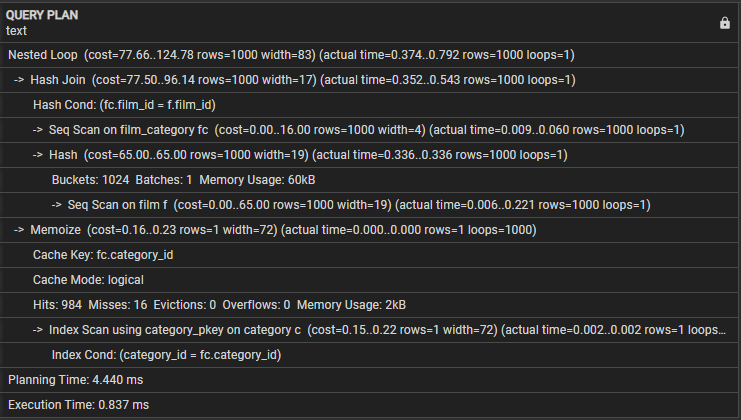
Давайте рассмотрим следующий план запроса:
- Вложенный цикл — это указывает на то, что соединение использует стратегию соединения с вложенным циклом.
- Hash Join — эта операция объединяет таблицу film_category и таблицы фильмов с использованием алгоритма хэш-соединения. Эта операция имеет стоимость 77,50 и оценивается в 1000 строк. Однако фактическое время, необходимое для этой операции, составляет от 0,254 до 0,439 миллисекунды, и она извлекает 1000 строк.
- Hash Cond — указывает, что условие соединения использует хеш-соединение для сопоставления столбцов film_id и film_category в таблицах фильмов.
- Seq Scan on film_category — эта операция выполняет последовательное сканирование таблицы film_category со стоимостью 16,00 и примерно 1000 строк. Фактическое время, необходимое для этой операции, составляет от 0,008 до 0,056 миллисекунды, и она извлекает 1000 строк.
- Seq Scan on film — запрос выполняет последовательное сканирование таблицы пленки с результирующими расчетными и фактическими затратами и строками в этой операции.
- Memoize — эта операция кэширует результаты соединения между таблицами film_category и film для последующего использования.
- Ключ кэша — указывает, что ключ кэша, который используется для запоминания, основан на столбце category_id из film_category.
- Режим кэша — указывает, что запрос использует режим логического кэша.
- Попадания, промахи, вытеснения, переполнения — три строки предоставляют статистику о кеше, количестве попаданий, промахов, вытеснений и переполнений во время выполнения. Этот блок также включает использование памяти во время выполнения запроса.
- Сканирование индекса с использованием category_pkey — показывает операцию, которая выполняет сканирование индекса в таблице категорий с использованием индекса первичного ключа.
- Условие индекса — это показывает, что сканирование индекса основано на условии, которое соответствует столбцу category_id в таблице категорий.
- Время планирования — в этой строке показано время, затраченное на планирование запроса, которое составляет 3,005 миллисекунды.
- Время выполнения. Наконец, в этой строке показано общее время выполнения запроса, которое составляет 0,745 миллисекунды.
Вот оно! Подробная информация о выполнении простого соединения в PostgreSQL.
Заключение
Вы узнали о возможностях и использовании инструкции EXPLAIN ANALYZE в PostgreSQL. Оператор EXPLAIN ANALYZE — это мощный инструмент для анализа и оптимизации запросов. Используйте этот инструмент для создания эффективных и менее ресурсоемких запросов.