Данные собираются ежедневно в огромных количествах, и управление большими данными является наиболее важным вариантом использования механизма Elasticsearch. Данные хранятся в базе данных аналитики в режиме реального времени, и пользователю разрешено извлекать данные, чтобы находить в них полезные знания с помощью запросов. Пользователь может применять запросы для поиска данных из нескольких индексов и отображения их в одном сегменте из реляционной базы данных.
В этом руководстве объясняются агрегаты Elasticsearch с примерами, использующими различные агрегаты.
Что такое агрегация Elasticsearch?
В Elasticsearch агрегация — это процесс объединения или группировки полей для извлечения информации из реляционной базы данных. Агрегацию в Elasticsearch можно рассматривать как СГРУППИРОВАТЬ ПО ПУНКТАМ или АГРЕГАТ() функция на языке SQL.
Как использовать агрегацию Elasticsearch?
Чтобы использовать агрегацию в Elasticsearch, пользователь должен иметь общее представление о своей базе данных. Давайте изучим синтаксис и его практическую реализацию:
Синтаксис
Чтобы найти данные из базы данных, синтаксис агрегации в движке Elasticsearch выглядит следующим образом:
'аггс' : {'имя_агрегации' : {
'тип_агрегации' : {
'поле' : 'имя_поля_документа'
}
Фрагменты выше:
-
- Он использует « аггс ключевое слово, объясняющее использование агрегации в запросе.
- имя_агрегации устанавливается пользователем в соответствии с необходимой информацией.
- После этого type_of_aggregation используется для получения данных.
- В последней строке используется поле ключевое слово, за которым следует имя атрибута из документа.
Пример 1: Агрегация в демонстрационных данных Kibana
В этом разделе объясняется агрегация с помощью примера, использующего демонстрационные данные из Kibana, предварительно подключившись к нему. После этого просто зайдите внутрь « Инструменты разработчика ”, выполнив поиск в строке поиска и щелкнув по нему:
Извлечение данных из выборочных данных
Просто используйте следующую команду, чтобы получить данные из « кибана_sample_data_logs ” в консоли Dev Tools:
ПОЛУЧАТЬ / кибана_sample_data_logs / _поиск
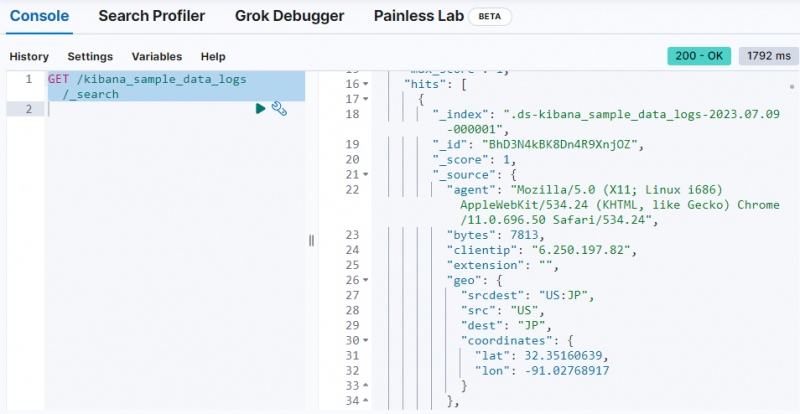
Вывод показывает, что данные были получены из « кибана_sample_data_logs ' индекс.
В следующем коде используется ПОЛУЧАТЬ запрос на « кибана_sample_data_log ' для поиска по нему с помощью агрегации value_count на ' клиент ' поле:
ПОЛУЧАТЬ / кибана_sample_data_logs / _поиск{ 'размер' : 0 ,
'аггс' : {
'ip_count' : {
'значение_количество' : {
'поле' : 'подсказка клиента'
}
}
}
}
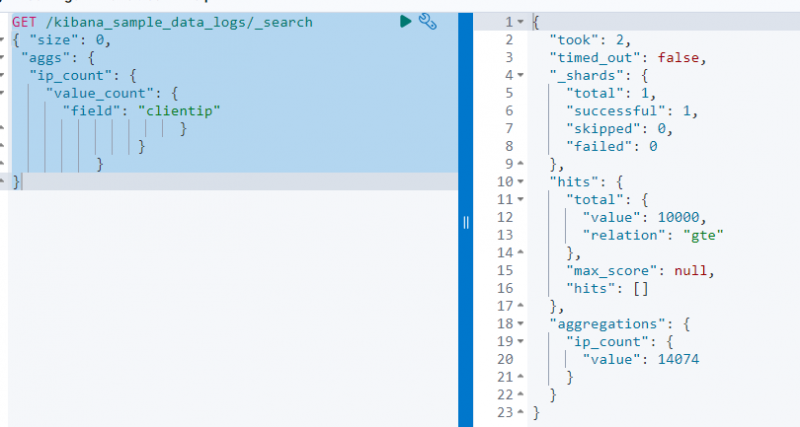
На приведенном выше снимке экрана показана агрегация на клиент поле со значением 14074 .
Важные агрегаты
Некоторые из важных агрегаций, которые используются для эффективного поиска данных в базе данных, упомянуты ниже:
В следующих примерах объясняются вышеупомянутые агрегации с использованием ПОЛУЧАТЬ просьба от ' kibana_sample_data_ecommerce ' индекс:
Агрегация мощности
В следующем коде используется « кардинальность агрегация на « артикул ” из данных электронной торговли. Выполнение этого кода приведет к агрегированию с одним значением для получения уникальных SKU из базы данных Elasticsearch:
ПОЛУЧАТЬ / kibana_sample_data_ecommerce / _поиск{
'размер' : 0 ,
'аггс' : {
'уникальный_скус' : {
'мощность' : {
'поле' : 'ску'
}
}
}
}
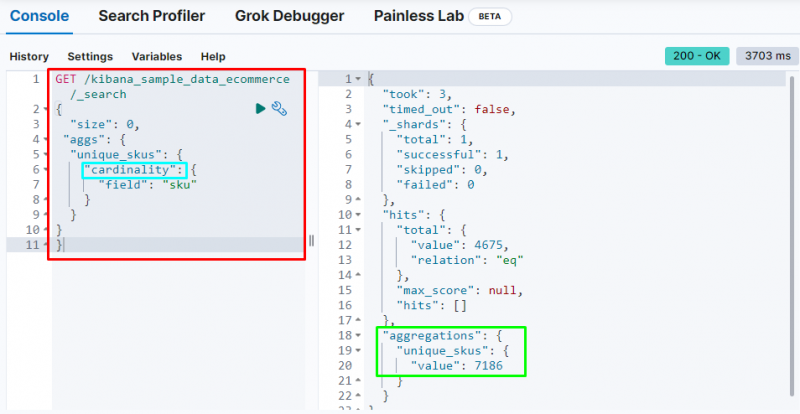
Он отображает кардинальность агрегация нахождение 7186 значений из указателя.
Агрегация статистики
Еще одним важным агрегированием является « статистика агрегация, которая используется для получения « считать », « мин », « Макс », « среднее ', и ' сумма » статистика из « Общая численность ' поле:
ПОЛУЧАТЬ / kibana_sample_data_ecommerce / _поиск{
'размер' : 0 ,
'аггс' : {
'количество_статистика' : {
'статистика' : {
'поле' : 'Общая численность'
}
}
}
}
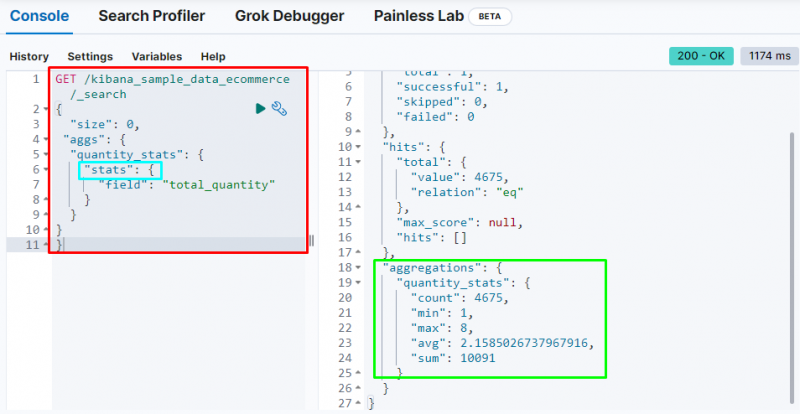
На приведенном выше снимке экрана показана статистика в выводе « Общая численность ' поле.
Агрегация фильтров
Агрегация фильтров используется для фильтрации данных на основе термина или фразы из базы данных, поскольку она содержится в следующем коде:
ПОЛУЧАТЬ / kibana_sample_data_ecommerce / _поиск{ 'размер' : 0 ,
'аггс' : {
'фильтр_агрегация' : {
'фильтр' : {
'срок' : {
'пользователь' : 'Эдди' } } ,
'аггс' : {
'цена_средняя' : {
'среднее' : {
'поле' : 'продукт.цена' } }
} } } }
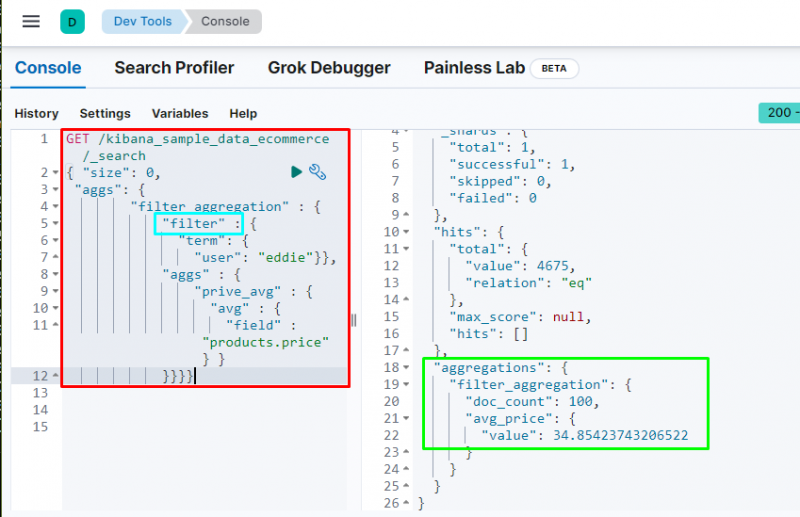
Выполнение кода будет фильтровать данные на основе « Эдди пользователя и отображает среднюю цену купленных товаров. На скриншоте выше показано, что пользователь Найдено 100 раз из данных и ценить принадлежащий среднее _ цена агрегация.
Агрегация терминов
Термин агрегация создает сегмент и сохраняет данные из поля в сегменте, а в следующем коде используется « пользователь ” для хранения своих данных в корзине:
ПОЛУЧАТЬ / kibana_sample_data_ecommerce / _поиск{
'размер' : 0 ,
'аггс' : {
'Term_Aggregation' : {
'условия' : {
'поле' : 'пользователь'
}
}
}
}
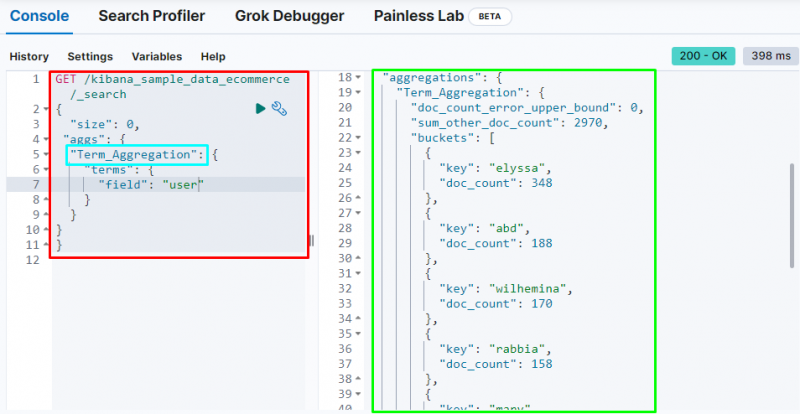
На следующем снимке экрана показано, что агрегация терминов создала сегменты для каждого пользователя и количества их документов.
Это все, что касается агрегации Elasticsearch и других важных агрегаций.
Заключение
В Elasticsearch агрегация используется для получения данных из агрегированных документов, и эти документы извлекаются из определенного поля. Объясняются некоторые важные агрегаты, которые используются для получения полезной информации из индексов. В этом руководстве объясняется агрегация Elasticsearch и демонстрируется процесс использования агрегации Elasticsearch.