В этой статье мы обсудим, как использовать API-интерфейс Elasticsearch для получения нескольких документов JSON на основе их идентификаторов. Кроме того, Elasticsearch позволяет использовать один запрос на получение для извлечения документов из индексов, используя только идентификаторы документов.
Давайте исследовать.
Синтаксис запроса
Ниже приведен синтаксис API множественного получения Elasticsearch:
ПОЛУЧИТЬ /_mget
ПОЛУЧИТЬ /<индекс>/_mget
API множественного получения поддерживает несколько индексов, что позволяет вам извлекать документы, даже если они не находятся в одном индексе.
Запрос поддерживает следующие параметры пути:
- <индекс> – Имя индекса, из которого извлекаются документы в соответствии с их идентификаторами.
Вы также можете указать другие параметры запроса, как показано ниже:
- предпочтение – Определяет предпочтительный узел или сегмент.
- В реальном времени – Если установлено значение true, операция выполняется в режиме реального времени.
- Обновить – Заставляет операцию обновлять целевые осколки перед получением указанных документов.
- Маршрутизация – Значение, которое используется для маршрутизации операций к определенному сегменту.
- Store_fields – Извлекает поля документа, хранящиеся в индексе, а не в самом документе.
- _источник – Логическое значение, определяющее, должен ли запрос возвращать поле _source или нет.
Для запроса требуется тело, которое включает следующие значения:
- Документы – Указывает документы, которые вы хотите получить. Кроме того, этот раздел поддерживает следующие атрибуты:
- _я бы – Уникальный идентификатор целевого документа.
- _индекс – индекс, содержащий целевой документ.
- Маршрутизация – Ключ для основного шарда документа.
- _источник – Если true, включаются все исходные поля; в противном случае он их исключает.
- _stored_fields – Сохраненные_поля, которые вы хотите включить.
- Идентификаторы – Идентификаторы документов, которые вы хотите получить.
Пример 1: выборка нескольких документов из одного индекса
В следующем примере показано, как использовать API множественного получения Elasticsearch для извлечения документов с определенными идентификаторами из индекса Netflix:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: отчетность' -H 'Тип контента: приложение/json' -d'{
'документы': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
Данный запрос должен получить документы с указанными идентификаторами из индекса Netflix. Полученный результат выглядит следующим образом:
{'документы': [
{
'_index': 'нетфликс',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_версия': 1,
'_seq_no': 0,
'_primary_term': 1,
'найдено': правда,
'_источник': {
'продолжительность': '90 мин',
'listed_in': 'Документальные фильмы',
'страна': 'США',
'date_added': '25 сентября 2021 г.',
'show_id': 's1',
'режиссер': 'Кирстен Джонсон',
'год_выпуска': 2020,
'рейтинг': 'PG-13',
'description': 'Когда ее отец приближается к концу своей жизни, режиссер Кирстен Джонсон инсценирует его смерть изобретательно и комично, чтобы помочь им обоим столкнуться с неизбежным.',
'тип': 'Фильм',
'title': 'Дик Джонсон мертв'
}
},
{
'_index': 'нетфликс',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_версия': 1,
'_seq_no': 12,
'_primary_term': 1,
'найдено': правда,
'_источник': {
'страна': 'Германия, Чехия',
'show_id': 's13',
'режиссер': 'Кристиан Швохов',
'год_выпуска': 2021,
'рейтинг': 'ТВ-МА',
'description': 'После того, как большая часть ее семьи погибла в результате теракта, молодую женщину по незнанию заманили присоединиться к той самой группировке, которая их убила.',
'тип': 'Фильм',
'title': 'Я Карл',
'продолжительность': '127 мин',
'listed_in': 'Драмы, международные фильмы',
«в ролях»: «Луна Ведлер, Яннис Нёвенер, Милан Пешель, Эдин Хасанович, Анна Фиалова, Марлон Босс, Виктор Боккар, Флер Жеффриер, Азиз Дьяб, Мелани Фуше, Елизавета Максимова»,
'date_added': '23 сентября 2021 г.'
}
}
]
}
Мы также можем упростить запрос, поместив идентификаторы документов в простой массив, как показано ниже:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: отчетность' -H 'Тип контента: приложение/json' -d'{
'ids': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
Предыдущий запрос должен выполнить аналогичное действие.
Пример 2: выборка документов из нескольких индексов
В следующем примере запрос извлекает несколько документов из разных индексов, как показано:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: отчетность' -H 'Тип контента: приложение/json' -d'{
'документы': [
{
'_index': 'нетфликс',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': 'Дисней',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
Полученный результат выглядит следующим образом:

Пример 3. Исключение определенных полей
Мы можем исключить определенные поля из данного запроса, используя параметры source_include и source_exclude.
Пример показан ниже:
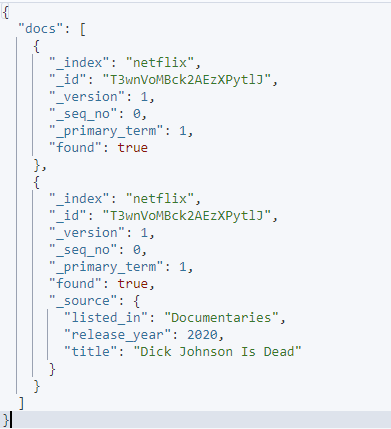
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: отчетность' -H 'Тип контента: приложение/json' -d'{
'документы': [
{
'_index': 'нетфликс',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_источник': ложь
},
{
'_index': 'нетфликс',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_источник': {
'include': [ 'перечислено_в', 'год_выпуска', 'название' ],
'исключить': [ 'описание', 'тип', 'дата_добавления' ]
}
}
]
}'
Данный запрос использует источник включения и исключения, чтобы указать, какие поля вы хотите получить в данном документе.
Полученный результат выглядит следующим образом:
Вывод
В этом посте мы обсудили основы работы с Elasticsearch API множественного получения, который позволяет вам получать несколько документов из разных источников на основе их идентификаторов. Не стесняйтесь изучать другие документы для получения дополнительной информации.
Удачного кодирования!