Этот пост иллюстрирует метод использования функций и классов синтаксического анализатора вывода через структуру LangChain.
Как использовать анализатор вывода через LangChain?
Синтаксические анализаторы вывода — это выходные данные и классы, которые могут помочь получить структурированный вывод из модели. Чтобы изучить процесс использования парсеров вывода в LangChain, просто выполните перечисленные шаги:
Шаг 1. Установите модули
Во-первых, запустите процесс использования выходных парсеров, установив модуль LangChain с его зависимостями для выполнения процесса:
пункт установить Лангчейн
После этого установите модуль OpenAI, чтобы использовать его библиотеки, такие как OpenAI и ChatOpenAI:
пункт установить опенай
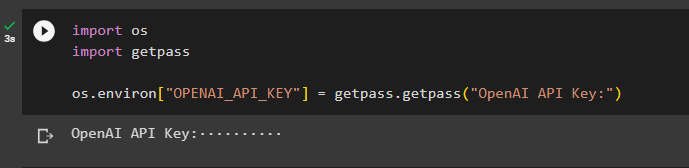
Теперь настройте среда для OpenAI используя ключ API от учетной записи OpenAI:
импортируйте нас
импортировать getpass
os.environ [ 'ОПЕНАЙ_API_KEY' ] = getpass.getpass ( «Ключ API OpenAI:» )
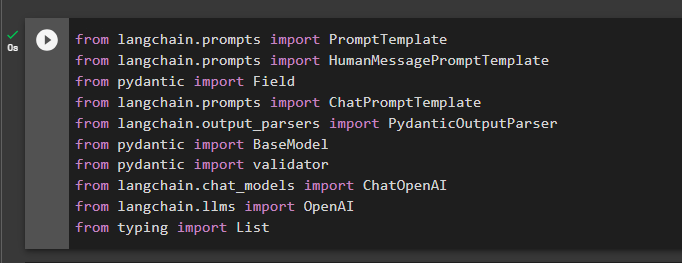
Шаг 2. Импортируйте библиотеки
Следующим шагом будет импорт библиотек из LangChain для использования парсеров вывода в фреймворке:
из langchain.prompts import HumanMessagePromptTemplate
из поля импорта pydantic
из langchain.prompts импорт ChatPromptTemplate
из langchain.output_parsers импортировать PydanticOutputParser
из pydantic импорта BaseModel
из валидатора импорта pydantic
из langchain.chat_models импортировать ChatOpenAI
из langchain.llms импортировать OpenAI
от ввода списка импорта
Шаг 3: Построение структуры данных
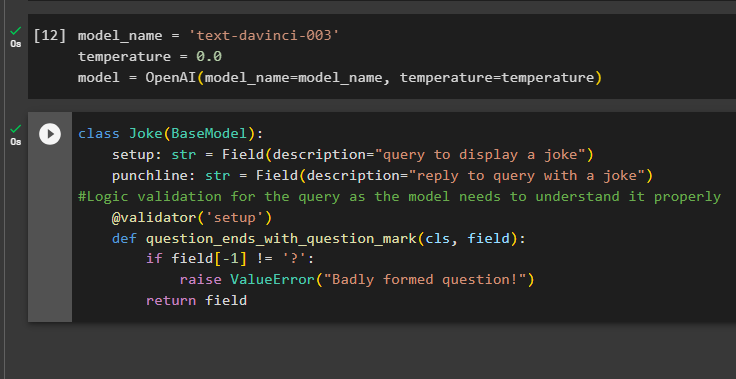
Построение структуры вывода — жизненно важное применение синтаксических анализаторов вывода в моделях большого языка. Прежде чем перейти к структуре данных моделей, необходимо определить имя модели, которую мы используем для получения структурированного вывода от анализаторов вывода:
температура = 0,0
модель = OpenAI ( название модели =имя_модели, температура = температура )
Теперь используйте класс Joke, содержащий BaseModel, чтобы настроить структуру вывода, чтобы получить шутку из модели. После этого пользователь может легко добавить собственную логику проверки с помощью класса pydantic, который может попросить пользователя ввести более сформированный запрос/подсказку:
классная шутка ( Базовая модель ) :настройка: str = Поле ( описание '=' 'запрос на отображение шутки' )
изюминка: str = Поле ( описание '=' 'ответить на вопрос шуткой' )
#Логическая проверка запроса, поскольку модель должна правильно его понять
@ валидатор ( 'настраивать' )
защита вопрос_ends_with_question_mark ( кл, поле ) :
если поле [ - 1 ] ! '=' '?' :
поднять ValueError ( «Плохо сформулированный вопрос!» )
возвращаться поле
Шаг 4. Настройка шаблона приглашения
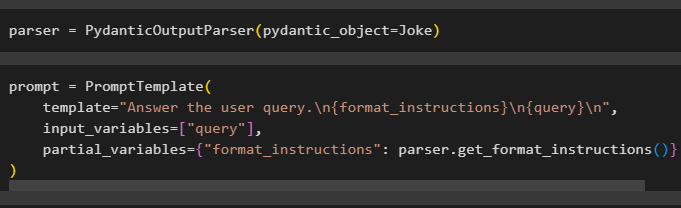
Настройте переменную синтаксического анализатора, содержащую метод PydanticOutputParser(), содержащий его параметры:
После настройки парсера просто определите переменную приглашения с помощью метода PromptTemplate() со структурой запроса/подсказки:
подсказка = PromptTemplate (шаблон '=' «Ответить на вопрос пользователя. \п {format_instructions} \п {запрос} \п ' ,
входные_переменные '=' [ 'запрос' ] ,
частичные_переменные '=' { 'format_instructions' : parser.get_format_instructions ( ) }
)
Шаг 5. Проверьте выходной анализатор
После настройки всех требований создайте переменную, которая будет назначена с помощью запроса, а затем вызовите метод format_prompt():
_input = Prompt.format_prompt ( запрос =joke_query )
Теперь вызовите функцию model(), чтобы определить выходную переменную:
выход = модель ( _input.to_string ( ) )Завершите процесс тестирования, вызвав метод parser() с выходной переменной в качестве параметра:
parser.parse ( выход ) 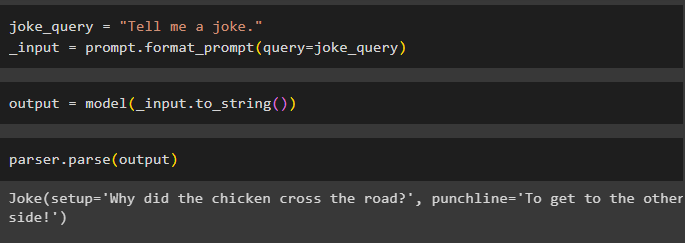
Вот и все, что касается процесса использования выходного парсера в LangChain.
Заключение
Чтобы использовать парсер вывода в LangChain, установите модули и настройте среду OpenAI, используя ее ключ API. После этого определите модель, а затем настройте структуру выходных данных с логической проверкой запроса, предоставленного пользователем. После настройки структуры данных просто установите шаблон приглашения, а затем протестируйте выходной синтаксический анализатор, чтобы получить результат из модели. В этом руководстве проиллюстрирован процесс использования синтаксического анализатора вывода в среде LangChain.